












![[图2:文章类型中元描述设置为“摘录”]](https://media.shuijingwanwq.com/2026/07/2-26-1024x668.png)

最近在复盘博客的搜索引擎表现时,发现了一个严峻的问题:网站在 Google 和 Bing 中有大量网页未被编入索引,数量逼近 15000 大关。经过在 Google Search Console 和 Bing Webmaster Tools 的深入排查,定位到了核心痛点,并梳理了后续的优化方案。在此记录,以便按优先级逐步推进。
一、 现状数据诊断
1. Google Search Console 索引概况
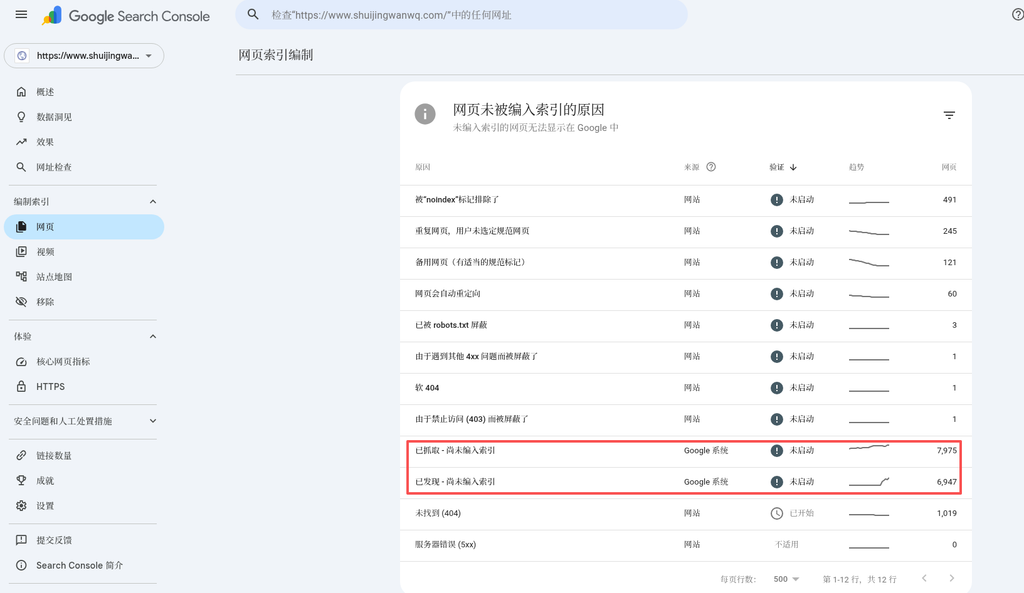
网页索引编制报告显示了令人触目惊心的数据,未编入索引的页面主要由以下原因构成:
- 已抓取-尚未编入索引:7,975 页
- 已发现-尚未编入索引:6,947 页
- 未找到 (404):1,019 页
- 服务器错误 (5xx):500 页
- 被 “noindex” 标记排除:491 页
- 重复网页,用户未选定规范网页:245 页
- 网页会自动重定向:60 页
- 其他(备用网页、4xx屏蔽、软404等):少量
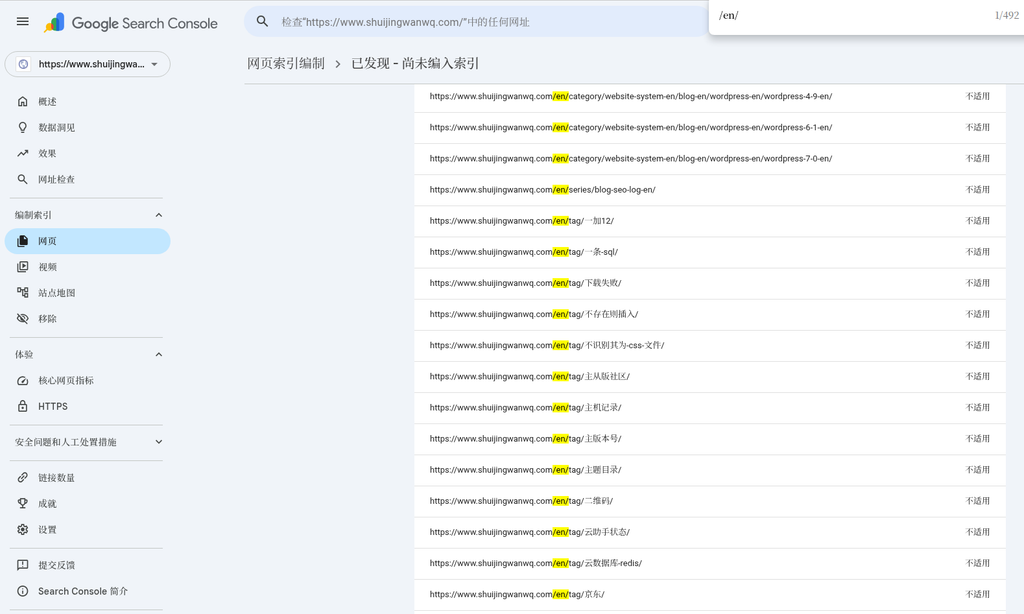
核心发现:在“已发现-尚未编入索引”的详情页中,大量充斥着 /en/tag/中文标签/ 格式的网址(如 /en/tag/下载失败/、/en/tag/主版本号/、/en/tag/京东/ 等)。这说明英文路径下混杂中文标签,是导致 Google 不愿索引的重灾区。
2. Bing Webmaster Tools 索引概况
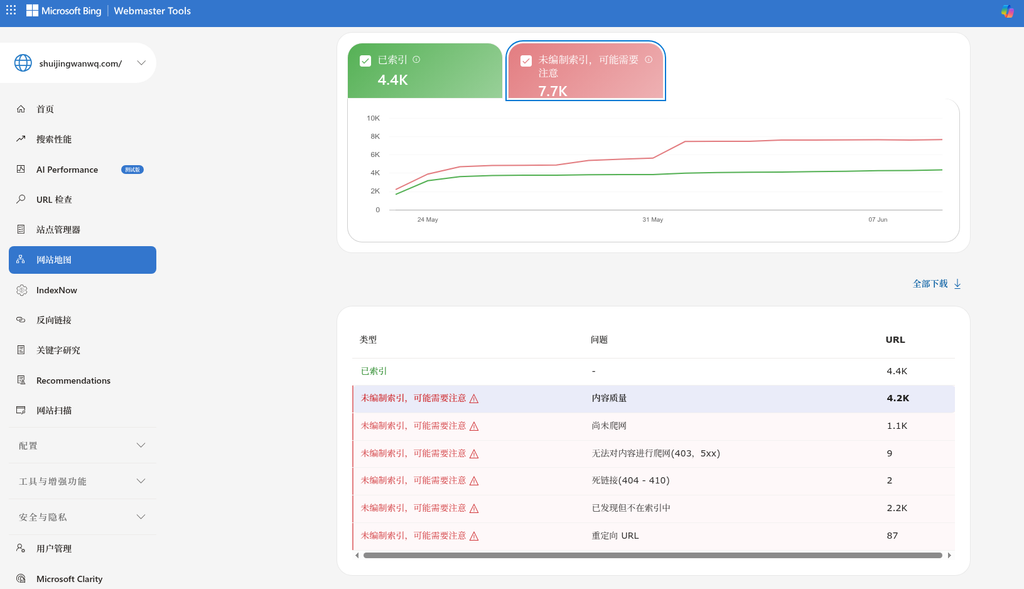
Bing 的数据同样不容乐观,整站索引情况如下:
- 已索引:4.4K
- 未编制索引,可能需要注意:7.7K
- 其中 内容质量 问题:4.2K
- 已发现但不在索引中:2.2K
- 重定向 URL:87
- 无法对内容进行爬网 (403, 5xx):9
- 死链接 (404-410):2
核心发现:Bing 明确指出了 4.2K 个页面存在“内容质量”问题,这与其在 Google 中表现为“已抓取-尚未编入索引”相呼应,本质上都是对低质量聚合页的抵制。
二、 问题成因剖析
综合两端数据,大量页面未被索引的根源主要有三点:
- 语言路径冲突与 URL 乱码:
/en/路径本应服务于英文用户,但标签却直接从中文库复制过来,导致 URL 中出现中文转义字符(如/en/tag/下载失败/),不仅语义混乱,也违背了 URL 规范化原则。 - 标签同义重复:中文中存在“管道”与“Channel”、“分类”与“Category”并存的标签,若直接翻译为英文,将产生同义重复标签,导致页面内容高度雷同。
- 薄内容泛滥:全站 8636 个英文标签中,有 6000 个标签下仅有 1 篇文章。这类标签页与单篇文章内容高度重合,属于典型的低质量自动生成页面,严重拉低了整站在搜索引擎中的信任评级。
三、 后续优化计划(按优先级排序)
鉴于时间与精力的平衡,我将按照以下优先级逐步处理:
🔴 P0:紧急止损与清理(立即执行)
- 清理空标签:删除 85 个文章数量为 0 的无效标签,消除死链隐患。
- 处理 404 与 5xx 错误:针对 GSC 报告的 1500 余个 404/5xx 错误进行排查修复,避免浪费抓取配额和影响蜘蛛抓取体验。
🟡 P1:质量控流(低成本高收益)
- 薄内容标签暂不删除,但加 noindex:考虑到单篇文章的标签未来可能会补充新内容,暂不删除这 6000 个薄内容标签。但会在代码层面对文章数 < 2 的标签页自动添加
<meta name="googlebot" content="noindex, follow">标签。这样既保留了页面结构,又明确告知搜索引擎暂不索引,避免拖累整站质量评分。
🟢 P2:底层架构重构(核心且耗时)
- 合并同义中文标签:在数据库中,将“管道”归并入“Channel”、“分类”归并入“Category”,消除冗余。
- 标签英译与 301 重定向:编写脚本,将剩余的 3200 个纯中文标签翻译为英文。翻译完成后,必须将原有的
/en/tag/中文/路径 301 重定向到对应的新英文路径(如/en/tag/download-failed/),以传递权重并防止产生新的 404 错误。
🔵 P3:细节规范(后续迭代)
- 处理重复网页:针对 245 个“重复网页,用户未选定规范网页”的报错,检查并完善
canonical标签设置。 - 检查重定向链路:排查 60 个自动重定向页面及 Bing 报错的 87 个重定向 URL,确保无多余的重定向跳转链。
总结:这 15000 个未索引页面不是一朝一夕形成的,解决起来也需要分步走。先通过清理和 noindex 止血,再通过翻译和 301 治本。期待后续优化完毕,索引量能迎来一波反弹!
WordPress 网站维护、性能优化与博客运营咨询
本站已持续运营超过 10 年,累计发布 1000+ 篇原创技术文章,长期实践 WordPress 网站建设、CDN / Cloudflare 配置、缓存优化、Google SEO、广告变现和多语言网站运营。
如果你的 WordPress 网站遇到访问慢、缓存异常、插件冲突、广告不显示、SEO 基础结构混乱、CDN 配置不确定等问题,可以联系我做一次远程技术排查。
适合以下用户:
✅ 个人博客站长
✅ WordPress 网站运营者
✅ 独立开发者与内容创作者
✅ SaaS 产品官网运营团队
✅ 希望优化网站速度与稳定性的站点
服务内容:
✅ WordPress 速度优化
✅ Cloudflare / CDN / 缓存配置排查
✅ 插件冲突与页面异常排查
✅ AdSense 广告显示问题排查
✅ SEO 基础结构检查
✅ 博客运营与商业化咨询
如需了解方案或交流相关问题,请直接联系我,并注明:WordPress 维护咨询。
联系方式:
Telegram:@shuijingwan
微信:13980074657
邮箱:shuijingwanwq@gmail.com
发表回复