Go study notes: channel basic usage and 4 core considerations (with code test)
In Go language concurrent programming, channel (pipe) is the core mechanism of communication between goroutines, which follows The design philosophy of communicating to share memory, rather than communicating through shared memory, fundamentally solves many hidden dangers of global variable lock synchronization. In the previous study, we understood the necessity of the channel through the factorial case. This article will focus on the basic definition of the channel, Initialization method, focus on dismantling 4 core precautions, combine code test to verify every detail, and record your own learning process and stepping experience.
1. Channel Basics: Definition and Initialization
Before using the channel, it is necessary to clarify its definition specification and initialization method – channel is a reference type, similar to map and slice, only declare that it cannot be used and cannot be initialized, and the data type stored must be specified, and can only be used to pass data of this type.
- Definition (declaration) format of channel
Basic definition syntax: var variable name chan data type
Among them, ‘data type’ specifies the type of data that the channel can store, and different types of channels cannot be mixed. Combined with the examples, the understanding is clearer, and the common declaration examples are as follows:
// 1. 声明一个存放int类型数据的Channel
var intChan chan int
// 2. 声明一个存放map[int]string类型数据的Channel
var mapChan chan map[int]string
// 3. 声明一个存放自定义Person类型数据的Channel
type Person struct {
name string
age int
}
var perChan chan Person
// 4. 声明一个存放Person指针类型数据的Channel
var perChan2 chan *Person
Note: Only the declared channel value is nil, the data cannot be written or read at this time, and it must be initialized through the make function before it can be used. This is the first small pit that novice is easiest to step on.
Initialization and Basic Use of Channel
Initialization syntax for channel: variable name = make(Chan data type, capacity)
Among them, ‘capacity’ (optional, no buffer by default) indicates the number of data that the channel can store. When the capacity is 0, there is no buffer channel, and when the capacity is greater than 0, there is a buffered channel.
2. Channel Core Precautions (4 scenarios, code test)
Combined with the test in the learning process, I disassembled the precautions for the use of the channel into 4 core scenarios, each of which is clearly presented through ‘code example → test results → problem analysis’ to avoid stepping on the pit.
Note 1: Only the data of the specified type can be stored in the channel
The channel specifies the data type when declared, which is fixed and strict – only the data of this type can be written to the channel, and the data of the type can only be read from the channel.
Test code (deliberate mixing type, verification error):
package main
func main() {
// 声明并初始化一个存放int类型的Channel
var intChan chan int
intChan = make(chan int, 2)
// (错误操作)
intChan <- "hello" // 尝试写入string类型数据,此处会编译报错
}
Test result (compilation error): as shown in Figure 1

/app/go-atguigu/channel-demo # go run main.go
# command-line-arguments
./main.go:12:13: cannot use "hello" (untyped string constant) as int value in send
Analysis: The error message clearly prompts ‘The String type cannot be sent to intChan as an int type’, which is the basic feature of the channel – strong type constraint. Such a design can ensure the security of data transmission and avoid logical errors caused by the mixing of different types of data, especially in complex concurrency scenarios, which can reduce many potential problems.
Note 2: After the channel data is full, the data cannot be written any more (will block)
The capacity of the buffered channel is fixed. When the number of data stored in the channel reaches the upper limit of the capacity, try to write the data, and the program It will block (pause execution) until there are other goroutines to read data from the channel and free up the idle position before continuing to write. If it is unbuffered channel, it will directly block after writing data until there is a goroutine to read the data.
Test code (out capacity write, validation blocking):
package main
import (
"fmt"
)
func main() {
//演示一下管道的使用
//1. 创建一个可以存放3个int类型的管道
var intChan chan int
intChan = make(chan int, 3)
//2. 看看intChan是什么
fmt.Printf("intChan 的值=%v intChan本身的地址=%p\n", intChan, &intChan)
//3. 向管道写入数据
intChan <- 10
num := 211
intChan <- num
intChan <- 50
// //如果从channel取出数据后,可以继续放入
//<-intChan
intChan <- 98 //注意点, 当我们给管写入数据时,不能超过其容量
}
Test results (program blocking): as shown in Figure 2
/app/go-atguigu/channel-demo # go run main.go
intChan 的值=0x77de188090 intChan本身的地址=0x77de168050
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
/app/go-atguigu/channel-demo/main.go:24 +0x112
exit status 2
/app/go-atguigu/channel-demo #
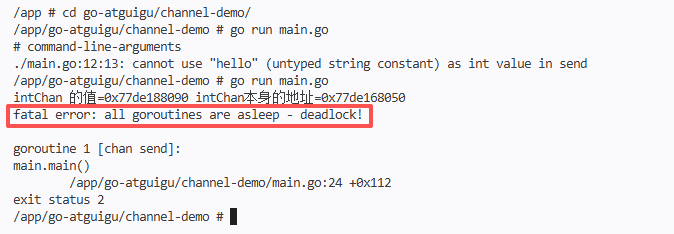
Analysis: Because there is no other goroutine to read the data in the channel, when writing the fourth data, the channel has no idle position, the program is blocked, and finally the deadlock (Deadlock) is triggered. It should be noted here: the capacity of the unbuffered channel is 0, the first data will be blocked, and the corresponding goroutine must be read to continue the execution.
Note 3: After fetching data from the channel, you can continue to write the data
This is a supplement to note 2 – the capacity of the channel is fixed, but the data is ‘dynamically flowing’: when a data is read from the channel , the length of the channel will be reduced by 1, freeing up an idle position. At this time, you can continue to write new data, without worrying about the insufficient capacity (as long as the initial capacity is not exceeded).
Test code (written after reading the data, verify feasibility):
package main
import (
"fmt"
)
func main() {
//演示一下管道的使用
//1. 创建一个可以存放3个int类型的管道
var intChan chan int
intChan = make(chan int, 3)
//2. 看看intChan是什么
fmt.Printf("intChan 的值=%v intChan本身的地址=%p\n", intChan, &intChan)
//3. 向管道写入数据
intChan <- 10
num := 211
intChan <- num
intChan <- 50
// //如果从channel取出数据后,可以继续放入
<-intChan
intChan <- 98 //注意点, 当我们给管写入数据时,不能超过其容量
//4. 看看管道的长度和cap(容量)
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 3, 3
}
Test results (normal execution, no error report):
/app/go-atguigu/channel-demo # go run main.go
intChan 的值=0x1ddbd65cc000 intChan本身的地址=0x1ddbd659a030
channel len= 3 cap=3
/app/go-atguigu/channel-demo #
Analysis: It can be seen from the results that after reading 1 data, the channel length changes from 3 to 2, freeing up a free position. At this time, write new data (98), and the length becomes 3 again, which is exactly in line with expectations. This feature allows Channels to achieve ‘dynamic flow’, suitable for producer-consumer models, and balance the generation and consumption speed of data.
Note 4: When there is no coroutine, the channel data will be fetched after fetching, and the deadlock will be reported
In the case that other goroutines are not started, when all the data in the channel is read, try to read the data, the program will block, and finally touch Deadlock – Because there are no other goroutines to write new data into the channel, the main thread will always wait and cannot continue to execute.
Test code (remove after the data is fetched, verify the deadlock):
package main
import (
"fmt"
)
func main() {
//演示一下管道的使用
//1. 创建一个可以存放3个int类型的管道
var intChan chan int
intChan = make(chan int, 3)
//2. 看看intChan是什么
fmt.Printf("intChan 的值=%v intChan本身的地址=%p\n", intChan, &intChan)
//3. 向管道写入数据
intChan <- 10
num := 211
intChan <- num
intChan <- 50
// //如果从channel取出数据后,可以继续放入
<-intChan
intChan <- 98 //注意点, 当我们给管写入数据时,不能超过其容量
//4. 看看管道的长度和cap(容量)
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 3, 3
//5. 从管道中读取数据
var num2 int
num2 = <-intChan
fmt.Println("num2=", num2)
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 2, 3
//6. 在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告 deadlock
num3 := <-intChan
num4 := <-intChan
num5 := <-intChan
fmt.Println("num3=", num3, "num4=", num4, "num5=", num5)
}
Test result (triggered deadlock): as shown in Figure 3
/app/go-atguigu/channel-demo # go run main.go
intChan 的值=0x2b443f34000 intChan本身的地址=0x2b443f02030
channel len= 3 cap=3
num2= 211
channel len= 2 cap=3
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
main.main()
/app/go-atguigu/channel-demo/main.go:41 +0x3bb
exit status 2
/app/go-atguigu/channel-demo #
Analysis: After the main thread has read all the data in the channel, and when trying to read it again, no other goroutine writes data to the channel, and the main thread will always block the read operation, which eventually leads to a deadlock. It needs to be noted here: if there are other goroutines to write data to the channel in the background, even if the current channel is empty, the read operation will wait for the data to be written, and will not die immediately. This is also the core principle of the channel to implement Goroutine synchronization.
3. Summary and learning experience
Through this study and code test, I have thoroughly mastered the basic usage of channel and 4 core precautions, and also deeply understood the design logic of channel as the core of Go concurrent communication. Summarize the key points:
- channel is a reference type, which must be declared and then initialized (make) before it can be used;
- Channel is strong type, it can only store and read the data of the specified type, and the mixed type will compile and report an error;
- After the buffer channel is full, it cannot continue to write (it will block), and after reading the data, it can be freed to continue writing;
- When there is no coroutine support, the channel data is fetched and then fetched, which will trigger a deadlock. This is the easiest pit for beginners to step on.
review the previous articleLearning to ‘Global Variable Lock Synchronization’, combined with the consolidation of this channel’s review, it can further highlight the core advantages of the channel – no need for manual locking to ensure concurrency safety, The precise synchronization between goroutines is realized with its blocking characteristics, which fundamentally avoids the time estimation problem and waste of resources caused by manual sleep. This review also further confirms that the core of Go concurrent programming lies in the control of details, even if the basic usage of the channel has been mastered, reorganize its capacity and class Key details such as type, reading and writing timing can still find the knowledge points that were ignored before, and repeatedly writing test code and verifying various scenarios is the key to consolidating knowledge points and avoiding stepping on pits.
The review of the basic usage and precautions of this channel has been completed, and on this basis, the advanced usage of the channel will be further reviewed, including unbuffered channel, one-way channel, select multiplexing, etc., etc. Combined with the actual scenarios such as the producer-consumer model, check and fill gaps, deepen understanding, and ensure that you can skillfully use the channel to achieve efficient communication and synchronization between Goroutines, truly understand the core logic of Go concurrent programming, and consolidate your own technical foundation.