

In the previous Go concurrency review, I focused on the many drawbacks of ‘global variable lock synchronization’ through factorial cases, especially the core question of ‘there are still hidden dangers when adding locks and hibernation’ Question – Manually set the sleep time to accurately match the rhythm of the execution of the protocol. If the resource is wasted too long, the result will be lost. Even if it is double locked, it is difficult to completely avoid the risk of resource competition. In this review, I will focus on the collaborative work of Goroutine and Channel, and through a complete practical case, to consolidate the core of the combination of the two. Heart logic, completely solve the previous concurrent synchronization hidden dangers left over, and at the same time, review the key details of the synergy between the coroutines and the pipeline, and consolidate your own concurrency programming foundation.
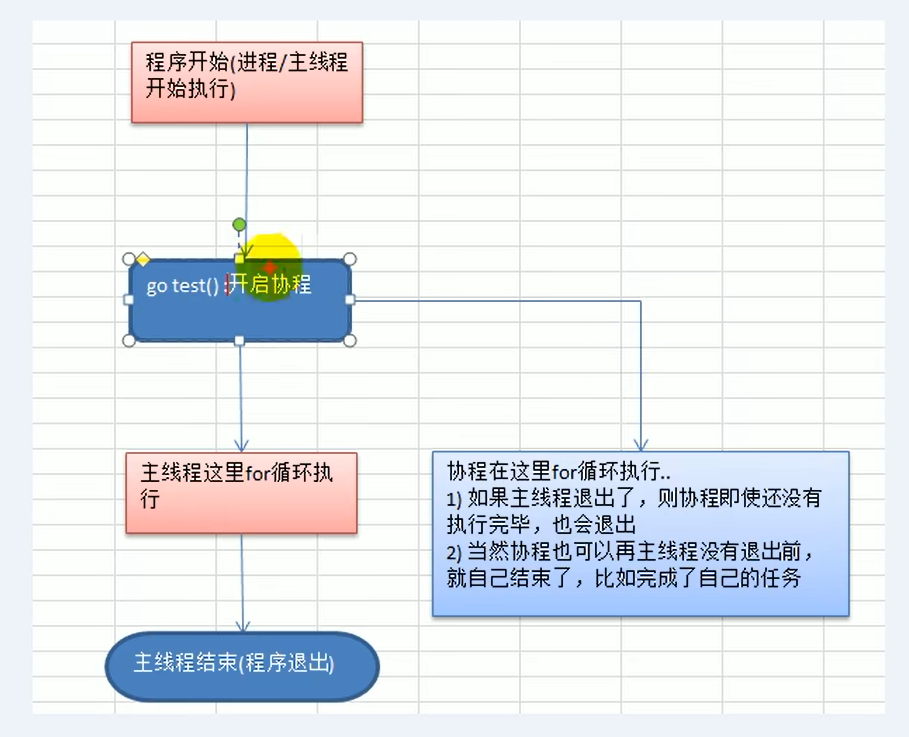
1. Review core goals: solve the inherent hidden dangers of ‘plus lock and sleep’
Looking back on the review of the previous round of factorial cases, I found that when using global variable lock synchronization to achieve multi-Goroutine communication, the biggest pain point is ‘synchronization of the main thread and coroutines’. In order for the main thread to wait for the coroutine to complete the task, I have to manually add time.sleep() to sleep, but this way is completely dependent on Subjective estimation, inability to adapt to the changes of system load and task complexity in actual operation, is essentially a solution of ‘treat the symptoms but not the root cause’.
The collaboration between Goroutine and Channel is the native solution provided by the Go language to solve this problem – no need to manually lock Concurrency is safe), no manual sleep is required (precise synchronization with the help of the channel blocking feature), so that the communication and synchronization between multiple coroutines is more efficient, safer and more flexible. The core goal of my review this time is to thoroughly solve the problem of ‘there are still hidden dangers in adding locks and hibernation’ through the practical case, thoroughly the underlying logic of the coordination between the two.
2. Demand and dismantling of collaborative case needs and ideas (personal review review)
The collaborative case I selected this time is the most basic and representative simplified version of the ‘Producer-Consumer’ model. The requirements are clear and realistic, and the core usage of Goroutine and Channel can be quickly connected.
- Open 1 WriteData coroutine and write 50 integers (producer) into the Intchan pipeline;
- Open a ReadData coroutine and read data from the same Intchan pipeline (consumer);
- The main thread must wait for the two coroutines of WriteData and ReadData to complete the work before they can exit normally, and prevent the problem of exiting the main thread after the coroutine has been executed.
From the perspective of personal review, the core idea of this case is actually very clear. The essence is to use the two characteristics of the channel to solve the synchronization problem. I have sorted out two core logics:
- Use IntChan as a data transfer pipeline to realize the communication between the two coroutines of WriteData and ReadData, without sharing global variables, avoid resource competition from the root, and replace the ‘global variable + mutex lock’ scheme I used before;
- Use ExitChan as a signal to synchronize the pipeline, and let the ReadData coroutine send ‘Completed’ to the main thread after reading all the data. ‘Signal’, the main thread waits for all the coroutines to complete by listening to the signal of ExitChan, replacing the manual sleep scheme I used before.
Here I focus on a detail: the shutdown of the pipeline (close()) is the key to working together. After the writeData coroutine has written all the data, it must close the Intchan, otherwise the readdata corout will be blocked in the read operation, resulting in a deadlock; while ex The shutdown of itchan can be selected according to the needs. The core role is to transmit the signal of ‘completion of the coroutines’ to the main thread to ensure that the main thread exits accurately, which is also a point that is easy to ignore in my previous review.
3. Complete code implementation and detailed review
Combined with the above ideas, I have sorted out the complete code implementation (the case code provided is still used), and at the same time, I reviewed the key details in it, and recorded the focus of my review when reviewing:
package main
import (
"fmt"
// 此处无需引入time包,彻底摆脱手动休眠的依赖
)
// writeData 协程:向intChan写入50个整数(生产者)
func writeData(intChan chan int) {
// 循环写入50个整数,逻辑简单但需注意循环边界
for i := 1; i <= 50; i++ {
// 向管道写入数据,有缓冲管道会自动调节写入节奏
intChan <- i
fmt.Println("writeData ", i)
// 此处可注释time.Sleep,验证Channel的缓冲特性,无需手动控制写入速度
// time.Sleep(time.Second)
}
// 关键操作:写入完成后关闭管道,告知readData协程“数据已写完”
close(intChan)
}
// readData 协程:从intChan读取数据,读取完成后向exitChan发送信号(消费者)
func readData(intChan chan int, exitChan chan bool) {
// 无限循环读取管道数据,直到管道关闭且无数据可读
for {
// 核心语法:v接收数据,ok判断管道是否关闭(true=有数据/未关闭,false=管道关闭且无数据)
v, ok := <-intChan
if !ok { // 管道关闭且无数据,说明读取完成,退出循环
break
}
fmt.Printf("readData 读到数据=%v\n", v)
}
// readData 读取完数据后,即任务完成
exitChan <- true
// 关闭exitChan(可选,此处关闭是为了让主线程读取信号后正常退出,避免阻塞)
close(exitChan)
}
func main() {
// 创建两个管道
// 1. 创建数据管道intChan:有缓冲管道,容量设为10,平衡读写节奏
// 复盘:容量可根据实际需求调整,此处10足够承载writeData的写入速度,避免频繁阻塞
intChan := make(chan int, 10)
// 2. 创建信号管道exitChan:用于传递“协程完成”信号,容量设为1即可(仅需传递1个信号)
exitChan := make(chan bool, 1)
// 启动两个协程,共享同一个intChan,实现协同工作
go writeData(intChan)
go readData(intChan, exitChan)
// 主线程监听exitChan,等待readData协程发送完成信号,精准退出
// 复盘:此处替代了此前的time.Sleep,彻底解决休眠时间估算不准的问题
for {
_, ok := <-exitChan
if !ok { // exitChan关闭且无信号,说明所有协程都已完成
break
}
}
// 主线程退出前可添加提示,验证协同效果
fmt.Println("所有协程执行完成,主线程正常退出")
}
Review of key details (individual review focus)
Combined with the code, I have sorted out several details that are easy to ignore but crucial from my own review perspective. These details directly determine the stability of the coordination between the coroutines and the pipeline, which is also the pit I have stepped on in the previous review:
Detail 1: The timing and function of the closure of the pipeline
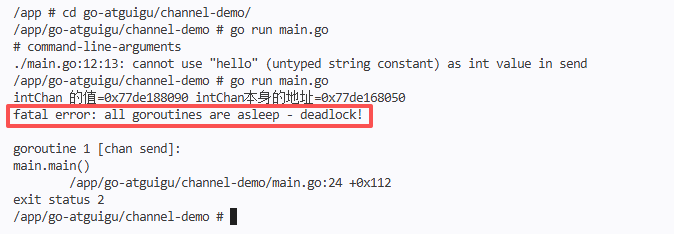
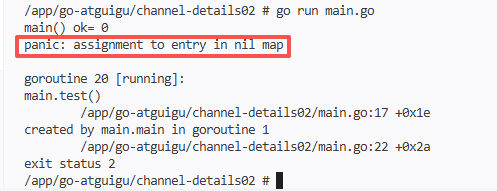
WriteData must call close(intchan) after writing 50 integers. I summed up the reason: if the pipeline is not closed, the readdata coroutine will always execute the for loop, try to read the data from intchan, when there is no data in the intchan, it will keep blocking, eventually causing the entire program to deadlock.
I will add the replay myself: close() can only be called by the ‘writer’, the reader cannot close the pipeline; after the pipeline is closed, the remaining in the pipeline can still be read After reading the data, the OK value will become False, which is the core basis for judging whether the pipeline is read and completed, and it is also the grammatical details that I need to keep in mind.
Detail 2: The core role of EXITCHAN – alternative manual hibernation
I sorted out the core role of ExitChan: to achieve ‘precise synchronization between the main thread and the coroutines’. After the ReadData coroutine reads all the data, writes true to the ExitChan, and the main thread confirms that the ReadData coroutine is completed by listening to the signal of the ExitChan; and The completion of the writeData coroutine is indirectly confirmed by the shutdown of IntChan (ReadData can read all the data, indicating that the writeData has been written and the pipeline is closed).
This completely solves the hidden danger of ‘locking and sleeping’ that I have encountered before – there is no need to estimate the execution time of the coroutine, the main thread only returns after receiving the ‘complete signal’. It does not waste resources, nor does it cause the coroutines to be destroyed before the execution is completed. This is also one of the core advantages of channel locking compared to global variables.
Detail 3: Choice and Advantage of Buffer Pipes
In this case, INTCHAN is set to a buffer pipe with capacity 10, not a buffer pipe. I concluded after review: the advantage of the buffer pipeline is ‘balanced reading and writing rhythm’ – writeData can write multiple data at one time (not exceeding Over-capacity), no need to wait for readdata to read immediately; readdata can read data according to its own rhythm to avoid frequent blocking.
I have tested it myself, if it is changed to an unbuffered pipeline, writeData will directly block when writing data, and it will not continue until the readdata reads the data. Continued writing, although it can also achieve coordination, the efficiency will be reduced, which is more suitable for scenarios with extremely high real-time data requirements. I have also recorded this in my own review notes.
Detail 4: Binding logic between coroutines and pipes
The two coroutines operate the same INTCHAN, which is the core of the communication between coroutines – Channel, as a ‘bridge’, realizes the safe transmission of data, without sharing global variables, and there is no need to manually add mutexes, which avoids the problem of resource competition from the root. This is the core advantage of channel compared to ‘global variable + locking’, and it is also the core logic that I need to focus on consolidating in this review.
4. Operational results and problem verification
I ran the above code and sorted out the core running results (intercepted part), so that I can review it for my own follow-up review: as shown in Figure 1
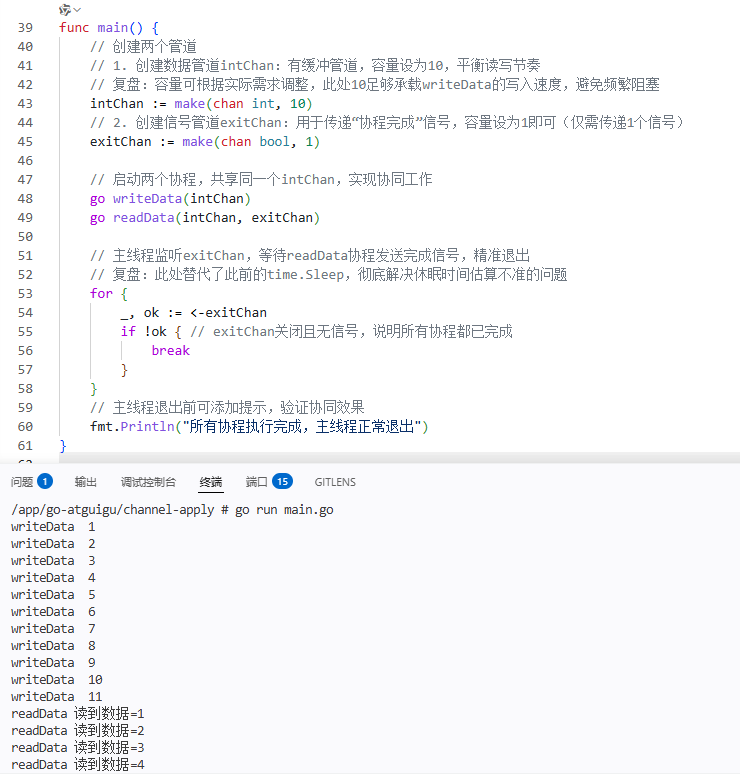
/app/go-atguigu/channel-apply # go run main.go
writeData 1
writeData 2
writeData 3
writeData 4
writeData 5
writeData 6
writeData 7
writeData 8
writeData 9
writeData 10
writeData 11
readData 读到数据=1
readData 读到数据=2
readData 读到数据=3
readData 读到数据=4
readData 读到数据=5
readData 读到数据=6
readData 读到数据=7
readData 读到数据=8
readData 读到数据=9
readData 读到数据=10
readData 读到数据=11
readData 读到数据=12
writeData 12
writeData 13
writeData 14
writeData 15
writeData 16
writeData 17
writeData 18
writeData 19
writeData 20
writeData 21
writeData 22
writeData 23
readData 读到数据=13
readData 读到数据=14
readData 读到数据=15
readData 读到数据=16
readData 读到数据=17
readData 读到数据=18
readData 读到数据=19
readData 读到数据=20
readData 读到数据=21
readData 读到数据=22
readData 读到数据=23
readData 读到数据=24
writeData 24
writeData 25
writeData 26
writeData 27
writeData 28
writeData 29
writeData 30
writeData 31
writeData 32
writeData 33
writeData 34
writeData 35
readData 读到数据=25
readData 读到数据=26
readData 读到数据=27
readData 读到数据=28
readData 读到数据=29
readData 读到数据=30
readData 读到数据=31
readData 读到数据=32
readData 读到数据=33
readData 读到数据=34
readData 读到数据=35
readData 读到数据=36
writeData 36
writeData 37
writeData 38
writeData 39
writeData 40
writeData 41
writeData 42
writeData 43
writeData 44
writeData 45
writeData 46
writeData 47
readData 读到数据=37
readData 读到数据=38
readData 读到数据=39
readData 读到数据=40
readData 读到数据=41
readData 读到数据=42
readData 读到数据=43
readData 读到数据=44
readData 读到数据=45
readData 读到数据=46
readData 读到数据=47
readData 读到数据=48
writeData 48
writeData 49
writeData 50
readData 读到数据=49
readData 读到数据=50
/app/go-atguigu/channel-apply #
All coroutines are executed, and the main thread exits normally
From the running results, I verified the following points and further consolidated the knowledge points:
- The WriteData coroutine successfully writes 50 integers, and the ReadData coroutine successfully reads all the data, and the two are normal together to achieve the expected effect;
- The main thread did not add any manual sleep, and only by listening to the signal of ExitChan, it is realized that the two coroutines are completed and then exited, which completely solves the hidden danger of my previous ‘sleep time estimate is not accurate’;
- The whole process does not need to be manually locked, and there is no resource competition error report, which confirms the concurrent safety characteristics of the channel, and makes me more convinced of the practicality of the channel in concurrent programming.
I also made a supplementary test: if the close(intchan) in the writedata coroutine is commented out, the deadlock will be triggered after running – the readdata corout will keep blocking in In the read operation, EXITCHAN cannot receive the completion signal, and the main thread is also blocking all the time, which once again verifies the importance of ‘the timing of the closure of the pipeline’, and also deepened my memory of this detail.
5. Review summary and core gains
This time, through the collaborative case review of goroutine and channel, I not only consolidated the basic usage of the two, but more importantly, Completely solved the core problem of ‘there are still hidden dangers in adding locks and hibernation’ in the previous factorial case, and combined with my own review situation, we have sorted out the following core gains:
- The collaboration between Goroutine and Channel is one of the best Go concurrent programming solutions I have at present – channel to achieve safe communication between coroutines, no need Sharing global variables and manual locking; its blocking feature realizes precise synchronization between the coroutines and the main thread, without manual sleep, and avoids synchronization hidden dangers from the root, and solves my previous core pain points.
- The closing of the pipeline (close()) is the key to collaborative work. After the writer completes the write, the pipeline must be closed, otherwise the reader will be blocked all the time, resulting in a deadlock; the reader passes ‘v, ok := <-chan’ to judge whether the pipeline is closed is the core syntax to realize the collaborative exit. This is the details of my review of the key memory this time.
- There is a choice of buffer and non-buffered pipeline. It needs to be combined with the actual scene. I have summarized the adaptation scene myself: there is a buffer pipe suitable for balanced read and write rhythms, improve Efficiency; no-buffer pipeline is suitable for scenarios with high real-time requirements, and realizes ‘sync blocking’ for read and write, and can be flexibly selected according to needs in subsequent development.
- Compared with the ‘global variable + locking’ scheme I used before, the advantage of channel is not only to simplify the code and avoid resource competition, but also in its ‘precision’ The ability of ‘quasi-synchronization’ makes concurrent programs more stable and maintainable, which also allows me to have a deeper understanding of the design philosophy of Go language ‘sharing memory through communication’.
In this review, I have completed the core practice of Goroutine and channel collaboration, and successfully solved the hidden dangers of concurrent synchronization. In the future, I will continue to review more complex collaborative scenarios (such as multi-producer, multi-consumer models), and further deepen the use of channel advanced usage. Understand, ensure that the two can be used flexibly in actual development, write efficient and safe concurrent code, and consolidate the core foundation of Go concurrent programming.
Go Backend Development & Architecture Consulting
I specialize in Go backend development, high-concurrency systems, API platforms, real-time communication services, and scalable backend architectures. All content shared in this series is based on real-world production experience.
Ideal For:
✅ High-concurrency applications
✅ API service platforms
✅ Real-time communication systems
✅ Microservices architecture
✅ Backend modernization projects
What I Offer:
✅ Go Backend Development
✅ API Platform Development
✅ Microservices Architecture Design
✅ Performance Optimization
✅ Long-Term Technical Support
Please contact me and mention: Go Project Consultation.
Contact Me:
Telegram: @shuijingwan
WeChat: 13980074657
Email: shuijingwanwq@gmail.com
Leave a Reply