






背景
我的站点 www.shuijingwanwq.com 是一个基于 WordPress 的内容站,网页数量约 2 万篇,日均访问量逐步上升。服务器采用阿里云 ECS(1核2GB),Web环境使用 OneinStack(Nginx + PHP-FPM + Redis + 阿里云 RDS MySQL)。网站一直运行平稳,直到某天晚上突然出现大面积 504 Gateway Time-out,后台尤其缓慢,几乎无法操作。其实前段时间也遇见过同样的问题,也做了初步的优化:我的个人博客,今天突然响应 504 的排查解决流程
问题现象
- 前端页面间歇性打不开,刷新偶有 504 错误;
- 后台
/wp-admin/admin.php加载极慢,时常超时; - 阿里云控制台显示 ECS CPU 使用率持续 100%;
- RDS 错误日志中出现大量
Aborted connection和Got an error reading communication packets。
排查过程
1. 服务器基础状态检查
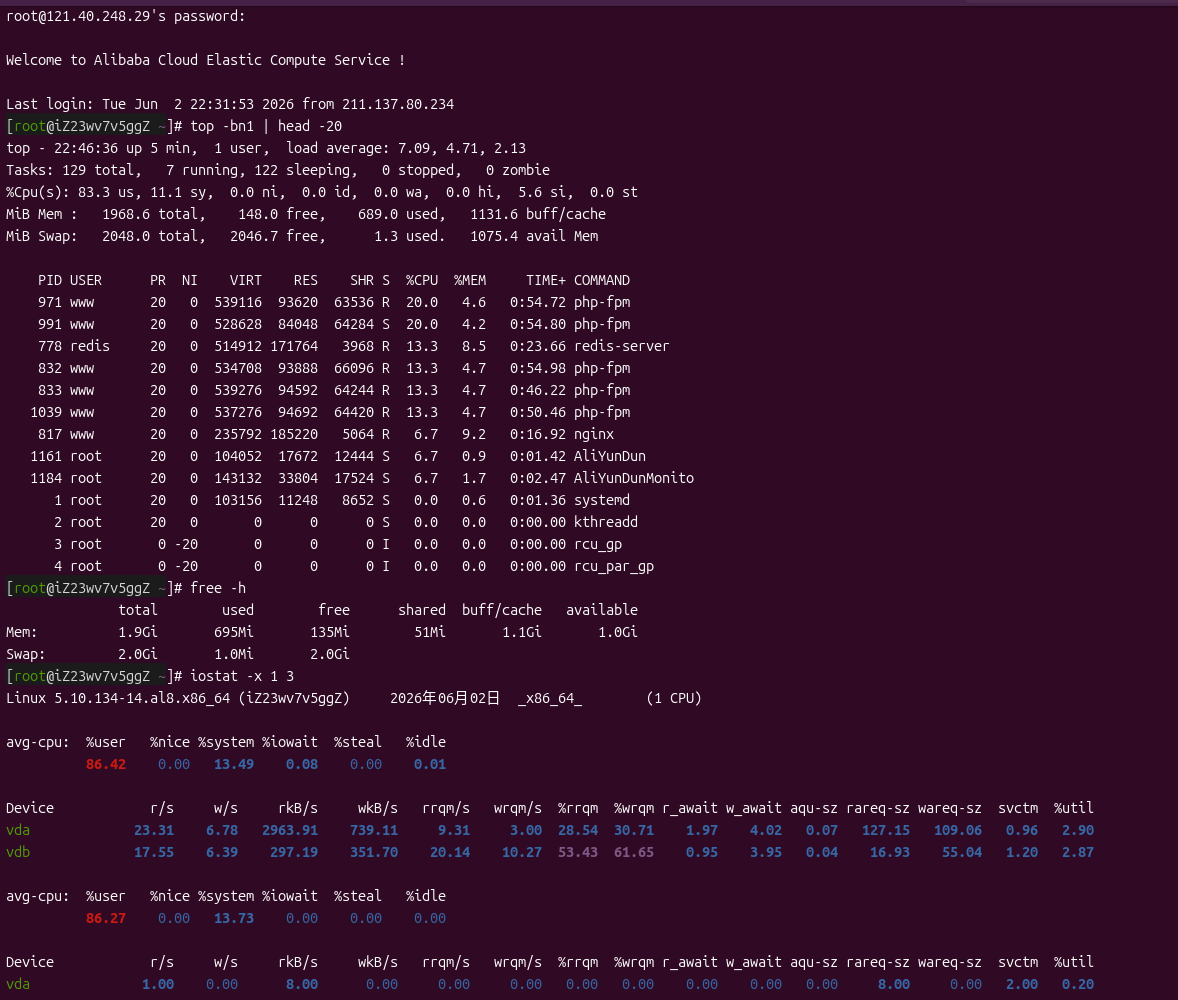
登录服务器,执行 top 发现负载高达 7.09(1核机器),%us 超过 80%,多个 php-fpm 进程占用 CPU 在 13%~20% 之间,redis-server 也占用 13% 左右,而 %id 为 0。内存剩余约 150MB,Swap 使用极少。iostat 显示磁盘 %util 很低,排除磁盘 I/O 瓶颈。如图1
2. PHP-FPM 配置分析
查看 /usr/local/php/etc/php-fpm.conf,发现几个严重问题:
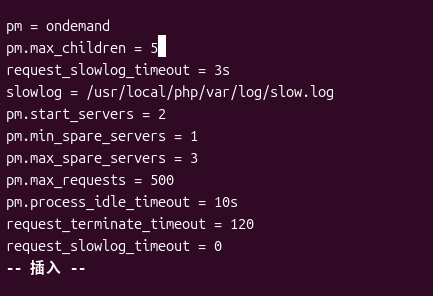
- 慢日志被重复定义且最后被覆盖为 0:
request_slowlog_timeout出现了两次,第一次3s,后面又设为0,导致慢日志从未生效。
;;;;;;;;;;;;;;;;;;;;;
; FPM Configuration ;
;;;;;;;;;;;;;;;;;;;;;
;;;;;;;;;;;;;;;;;;
; Global Options ;
;;;;;;;;;;;;;;;;;;
[global]
pid = run/php-fpm.pid
error_log = log/php-fpm.log
log_level = warning
emergency_restart_threshold = 30
emergency_restart_interval = 60s
process_control_timeout = 5s
daemonize = yes
;;;;;;;;;;;;;;;;;;;;
; Pool Definitions ;
;;;;;;;;;;;;;;;;;;;;
[www]
listen = /dev/shm/php-cgi.sock
listen.backlog = -1
listen.allowed_clients = 127.0.0.1
listen.owner = www
listen.group = www
listen.mode = 0666
user = www
group = www
pm = ondemand
pm.max_children = 5
request_slowlog_timeout = 3s
slowlog = /usr/local/php/var/log/slow.log
pm.start_servers = 2
pm.min_spare_servers = 1
pm.max_spare_servers = 3
pm.max_requests = 500
pm.process_idle_timeout = 10s
request_terminate_timeout = 120
request_slowlog_timeout = 0
pm.status_path = /php-fpm_status
slowlog = var/log/slow.log
rlimit_files = 51200
rlimit_core = 0
catch_workers_output = yes
;env[HOSTNAME] = iZ23wv7v5ggZ
env[PATH] = /usr/local/bin:/usr/bin:/bin
env[TMP] = /tmp
env[TMPDIR] = /tmp
env[TEMP] = /tmp
- 超时设置不协调:PHP-FPM 的
request_terminate_timeout = 120s,而 Nginx 未设置fastcgi_read_timeout(默认 60s),导致 PHP 执行超过 60 秒时 Nginx 先返回 504,但 PHP-FPM 仍在执行,浪费资源。
3. Nginx 配置缺失
站点配置文件 /usr/local/nginx/conf/vhost/www.shuijingwanwq.com.conf 中的 PHP 处理部分缺少 fastcgi_read_timeout,默认 60 秒超时。
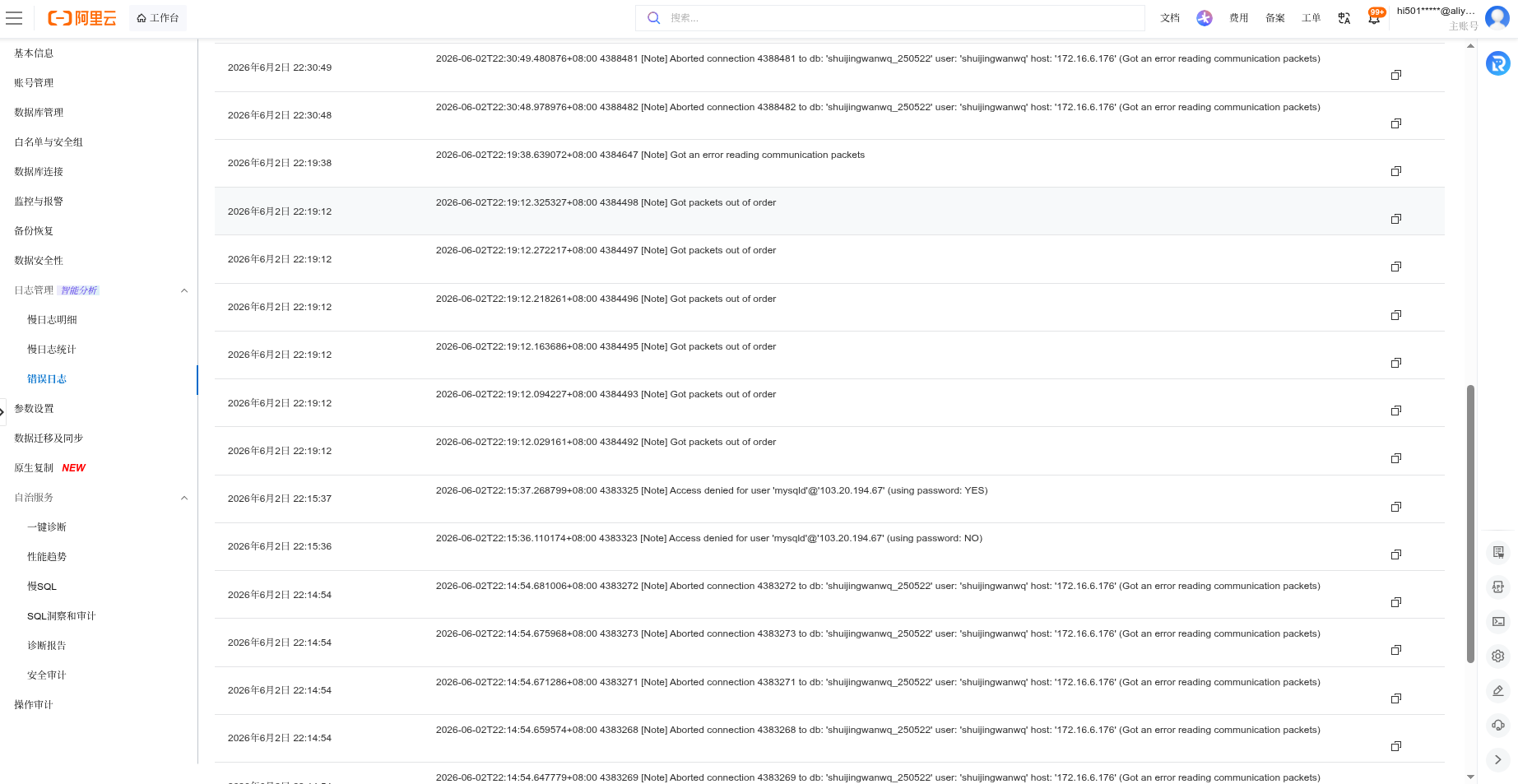
4. RDS 错误日志分析
RDS 控制台错误日志出现大量:
Aborted connection ... (Got an error reading communication packets)
Got packets out of order
这表明 PHP 与 MySQL 之间的连接被异常中断,通常是因为 PHP 执行时间过长,超过了 MySQL 的 wait_timeout 或 PHP 进程提前终止。如图3
5. 慢日志为空
无论是 PHP 慢日志(/usr/local/php/var/log/slow.log)还是 RDS 慢查询日志(控制台慢日志明细),均无数据。原因是 PHP 慢日志被关闭,RDS 的 long_query_time 默认 10 秒,当前查询可能耗时 2~5 秒但未被记录。
解决方案
1. 修正 PHP-FPM 配置
采用 ondemand 模式,适合 1 核小内存机器,空闲时释放进程。最终配置如下:如图4
;;;;;;;;;;;;;;;;;;;;;
; FPM Configuration ;
;;;;;;;;;;;;;;;;;;;;;
;;;;;;;;;;;;;;;;;;
; Global Options ;
;;;;;;;;;;;;;;;;;;
[global]
pid = run/php-fpm.pid
error_log = log/php-fpm.log
log_level = warning
emergency_restart_threshold = 30
emergency_restart_interval = 60s
process_control_timeout = 5s
daemonize = yes
;;;;;;;;;;;;;;;;;;;;
; Pool Definitions ;
;;;;;;;;;;;;;;;;;;;;
[www]
listen = /dev/shm/php-cgi.sock
listen.backlog = -1
listen.allowed_clients = 127.0.0.1
listen.owner = www
listen.group = www
listen.mode = 0666
user = www
group = www
pm = ondemand
pm.max_children = 5
pm.process_idle_timeout = 10s
pm.max_requests = 500
request_terminate_timeout = 120s
request_slowlog_timeout = 3s
slowlog = /usr/local/php/var/log/slow.log
catch_workers_output = yes
env[PATH] = /usr/local/bin:/usr/bin:/bin
env[TMP] = /tmp
env[TMPDIR] = /tmp
env[TEMP] = /tmp
- 删除了与
ondemand冲突的pm.start_servers、pm.min/max_spare_servers。 - 确保慢日志唯一且生效。
2. Nginx 增加超时
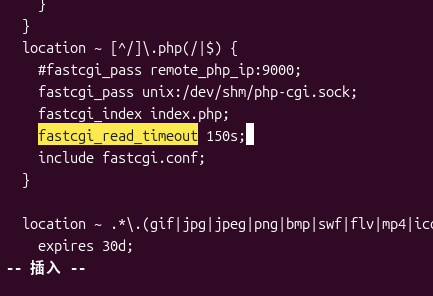
在 PHP 处理 location 中添加:
fastcgi_read_timeout 150s;
使 Nginx 超时时间略大于 PHP-FPM 的 120 秒,避免 Nginx 提前中断。如图5
3. 调整 RDS 慢查询阈值
登录 RDS 控制台 → 参数设置 → 将 long_query_time 从 100 改为 1 秒,以便捕获更多慢 SQL。如图7
4. 重启服务
systemctl restart php-fpm
systemctl restart nginx
结果
调整后网站访问恢复正常,CPU 使用率回落至正常水平,后台响应明显提升。RDS 错误日志中的连接中断大幅减少。尽管 RDS 慢日志仍未发现特别慢的 SQL,但整体瓶颈已基本解除。
后续优化建议
尽管当前已经恢复,但考虑到数据量已达 2 万篇且流量持续增长,1 核 2GB 的配置仍显吃力。以下是后续可采取的优化措施:
✅ 1. 硬件升级(根本性解决)
- 升级 ECS 配置:至少 2 核 4GB,推荐 4 核 8GB。升级后可将 PHP-FPM 模式改为
dynamic,pm.max_children调整至 10~15,并发处理能力大幅提升。 - RDS 规格提升:如果慢查询增多或连接数经常打满,可考虑升级 RDS 内存或开启只读实例。
✅ 2. 使用 CDN 加速静态资源
阿里云 CDN + OSS 组合:
- 将站点图片、CSS、JS 等静态文件上传至 OSS,并开启 CDN 加速。
- 配置 WordPress 插件(如 AliOSS)自动同步媒体库。
- 效果:减轻 ECS 带宽压力,加快全国各地访问速度。
✅ 3. 页面缓存深度优化
已安装 W3 Total Cache,建议检查:
- 页面缓存 使用磁盘增强或 Redis。
- 对象缓存 确认使用 Redis 驱动。
- 数据库缓存 同样使用 Redis,避免磁盘 I/O。
- 开启 Opcode 缓存(如 Zend OPcache)。
✅ 4. 数据库专项优化
- 定期执行
OPTIMIZE TABLE优化wp_posts、wp_postmeta等大表。 - 为常用查询字段添加索引,例如
post_date、meta_key。 - 使用 Index WP MySQL For Speed 插件自动分析并添加缺失索引。
✅ 5. 监控与告警
- 安装阿里云云监控,对 CPU、内存、RDS 连接数设置阈值告警。
- 编写每天定时脚本,检查 PHP 慢日志和 RDS 慢日志,若发现新慢请求则发送邮件。
✅ 6. 定期清理与维护
- 清理过期草稿、回收站文章、无用的 postmeta 数据。
- 禁用或删除不常用的插件,减少后台加载项。
- 配置 WP-Cron 改用系统 crontab 触发,避免每次访问都检查任务队列。
总结
这次 504 故障的根本原因是 服务器配置与业务规模不匹配,加上 PHP-FPM 参数设置错误,导致 CPU 耗尽、连接中断。通过修正配置、增加超时、开启慢日志,问题得以解决。长期来看,升级硬件和引入 CDN 是必经之路。
希望这篇记录能为遇到类似问题的朋友提供参考。如果你也有 WordPress 高负载优化经验,欢迎交流!
WordPress 网站维护、性能优化与博客运营咨询
本站已持续运营超过 10 年,累计发布 1000+ 篇原创技术文章,长期实践 WordPress 网站建设、CDN / Cloudflare 配置、缓存优化、Google SEO、广告变现和多语言网站运营。
如果你的 WordPress 网站遇到访问慢、缓存异常、插件冲突、广告不显示、SEO 基础结构混乱、CDN 配置不确定等问题,可以联系我做一次远程技术排查。
适合以下用户:
✅ 个人博客站长
✅ WordPress 网站运营者
✅ 独立开发者与内容创作者
✅ SaaS 产品官网运营团队
✅ 希望优化网站速度与稳定性的站点
服务内容:
✅ WordPress 速度优化
✅ Cloudflare / CDN / 缓存配置排查
✅ 插件冲突与页面异常排查
✅ AdSense 广告显示问题排查
✅ SEO 基础结构检查
✅ 博客运营与商业化咨询
如需了解方案或交流相关问题,请直接联系我,并注明:WordPress 维护咨询。
联系方式:
Telegram:@shuijingwan
微信:13980074657
邮箱:shuijingwanwq@gmail.com
发表回复