Blog SEO Diagnostic Records: Causes and Optimization List of Nearly 15000 Pages Not Indexed
A serious problem was found when reviewing the search engine performance of the blog recently: the website has a large number of pages that are not indexed in Google and Bing, and the number is close to the 15,000 mark. After in-depth investigations in Google Search Console and Bing Webmaster Tools, the core pain points have been positioned, and the subsequent optimization solutions have been sorted out. This is recorded so that it can be progressively progressed at priority.
1. Current status data diagnosis
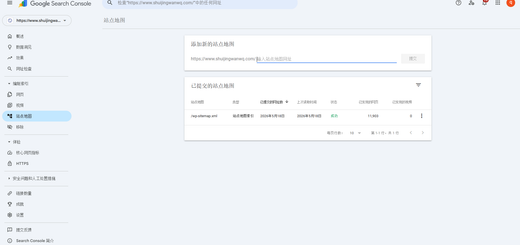
1. Google Search Console Index Overview
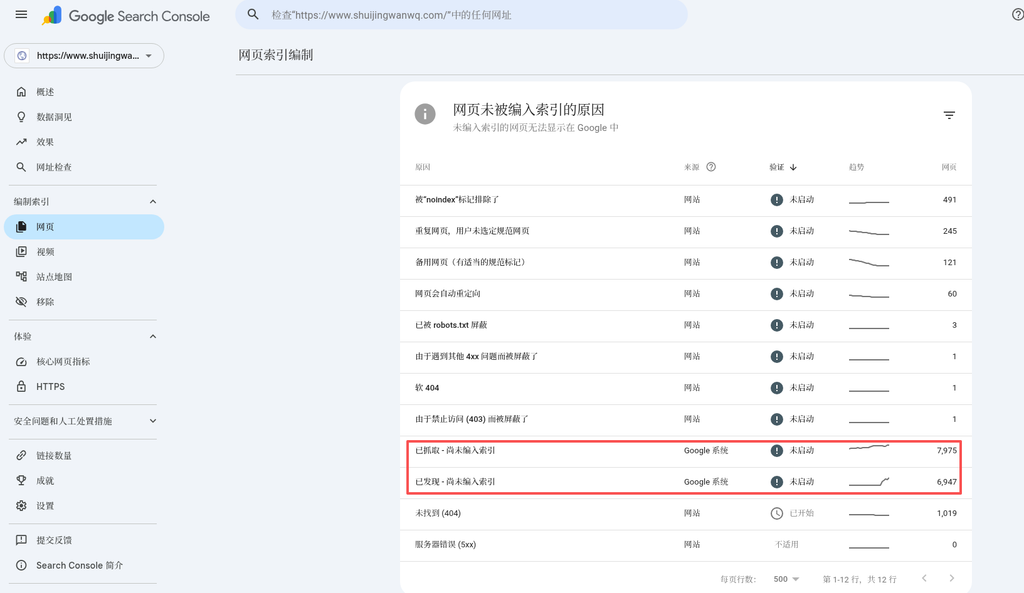
The web indexing report shows stunning data, and pages that are not indexed are mainly composed of the following reasons:
- Crawled – not indexed yet:7,975 pages
- Discovered – not indexed: 6,947 pages
- not found (404):1,019 pages
- Server error (5xx): 500 pages
- Excluded by ‘noindex’ tag:491 pages
- Duplicate web pages, users do not select canonical web pages: 245 pages
- Web pages are automatically redirected:60 pages
- Others (alternate web page, 4xx shield, soft 404, etc.): a small amount
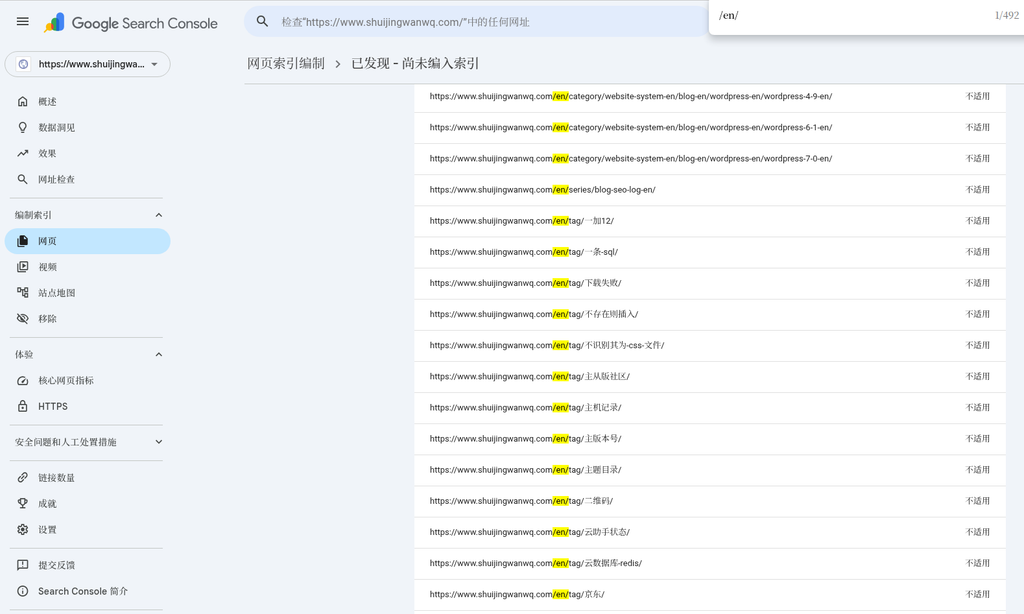
core discovery: In the details page of ‘Discovered-Not Indexed’, it is flooded with /en/tag/Chinese label/ URLs of the format (such as /en/tag/download failed/,/en/tag/main version number/,/en/tag/Jingdong/ etc.). This shows that the mixed Chinese label under the English path is the hardest hit area that Google is reluctant to index.
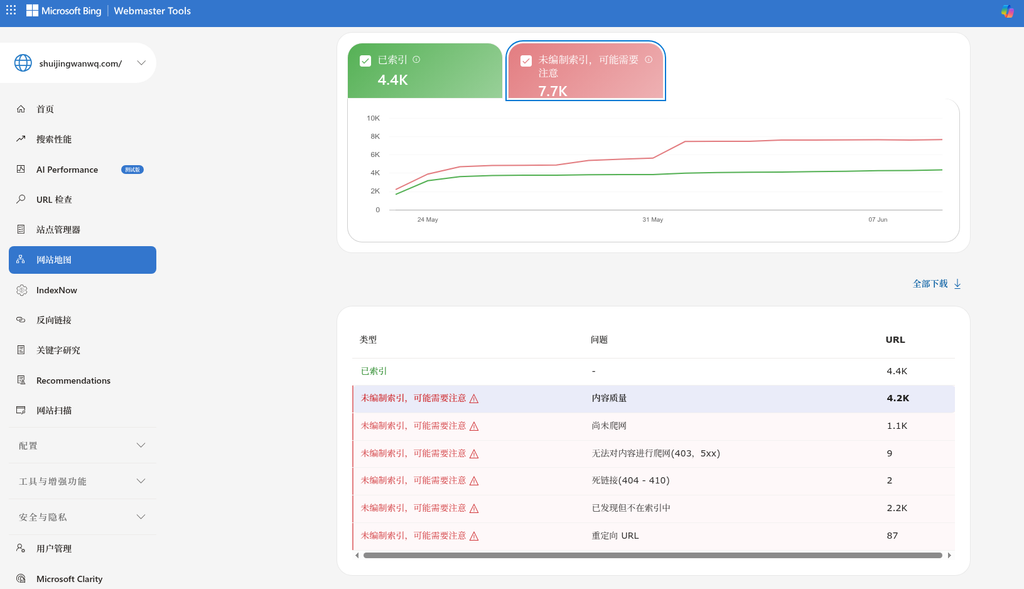
2. Bing Webmaster Tools Index Overview
The data of Bing is also not optimistic, and the index of the entire site is as follows:
- Indexed: 4.4k
- No indexing, may need to be careful: 7.7K
- Among quality of content Question: 4.2K
- Found but not in the index: 2.2K
- Redirect URL: 87
- Unable to crawl content (403, 5xx): 9
- Dead Link (404-410): 2
core discovery: Bing clearly pointed out the ‘content quality’ problem of 4.2k pages, which echoes its performance in Google as ‘crawled – not indexed’, which is essentially a resistance to low-quality aggregate pages.
Second, the cause of the problem
To synthesize the data at both ends, the root causes of a large number of pages that are not indexed are mainly three points:
- Language Path Conflict with URL Garbage:
/en/The path should serve English users, but the label is directly copied from the Chinese library, resulting in Chinese escape characters (such as/en/tag/download failed/), not only is the semantic confusion, but also violates the principle of URL normalization. - Tag Synonymous Repeat: There are labels in Chinese that coexist with ‘pipeline’, ‘channel’, ‘category’ and ‘category’.
- flood of content: Among the 8636 English labels of the whole station, there are only 1 article under 6000 labels. This type of tab pages highly overlap the content of a single article, which is a typical low-quality automatic generation page, which seriously lowers the trust rating of the entire search engine.
3. Subsequent optimization plan (ordered by priority)
Given the balance of time and energy, I will step by step by step by step:
🔴 P0: Emergency Stop Loss and Cleanup (Execute Now)
- Clear empty labels: Delete 85 invalid tags with the number of articles 0 to eliminate the hidden danger of dead chain.
- Handling 404 and 5xx errors: Check and fix the more than 1500 404/5xx errors reported by the GSC, avoiding waste of crawling quotas and affecting spider crawling experience.
🟡 P1: Quality control flow (low cost and high yield)
- The thin content label will not be deleted for the time being, but add noindex: Considering that the label of a single article may add new content in the future, the 6000 thin content tags will not be deleted for the time being. but at the code levelNumber of articles < 2 tabsautomatic addition
<meta name='GoogleBot' content='noindex, follow'>label. This not only retains the page structure, but also clearly informs the search engine that it does not index for the time being, so as to avoid dragging down the quality score of the entire site.
🟢 P2: The underlying architecture refactoring (core and time consuming)
- Merge Synonymous Chinese Tags: In the database, the ‘pipe’ is merged into ‘Channel’, ‘Classification’ is merged into ‘Category’, and redundancy is eliminated.
- Tag English translation and 301 redirect: Write a script to translate the remaining 3200 pure Chinese labels into English. After the translation is completed,The original
/en/tag/Chinese/Path 301 Redirect to the corresponding new English path(such as/en/tag/download-failed/) to pass weights and prevent new 404 errors.
🔵 P3: Details specification (subsequent iteration)
- Handling duplicate web pages: Check and improve the errors of the 245 ‘duplicate web pages, the user did not select the canonical web page’
canonicalLabel settings. - Check redirect link: Check the 87 redirect URLs of the 60 automatic redirect pages and Bing errors, and ensure that there are no redundant jump chains.
Summary: These 15,000 unindexed pages are not formed overnight, and they also need to go step by step. Stop the bleeding first by cleaning and noindex, and then treat the root cause by translation and 301. Looking forward to the completion of the follow-up optimization, the index volume can usher in a wave of rebound!