
WP 博客多语言化实操





(5) 博客菜单翻译实操

















在上一篇文章中,我们验证了大语言模型无法胜任大量结构化数据的精准匹配工作。为了彻底清除 /en/tag/ 路径下的中文冗余网址,我们必须回归工程化方案。
本文将作为一篇实战教程,手把手记录如何从零开始,通过 Go 语言结合百度翻译 API,完成标签的自动化映射处理。
第一步:申请百度翻译 API 凭证
要实现中文标签到英文的精准转换,我们需要借助成熟的机器翻译服务。这里选择百度翻译开放平台,它提供了基础的通用文本翻译 API,标准版每月有免费额度,完全足够此次清洗任务使用。
登录百度翻译开放平台,在控制台开通“通用文本翻译”服务。
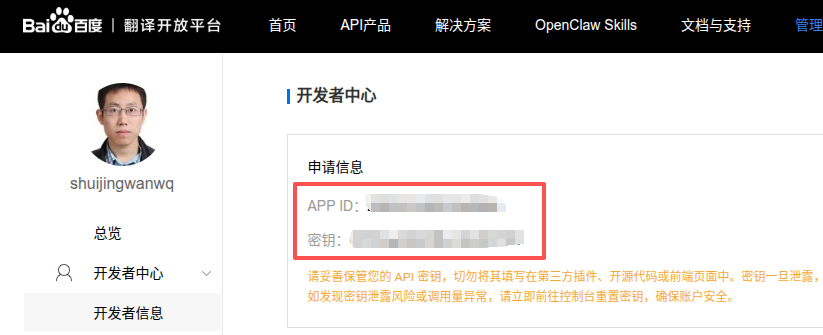
开通后,进入开发者中心,在此页面获取你的 APP ID 和 密钥。请妥善保管这两项凭证,后续代码中将作为环境变量调用。
第二步:在 GitHub 初始化项目
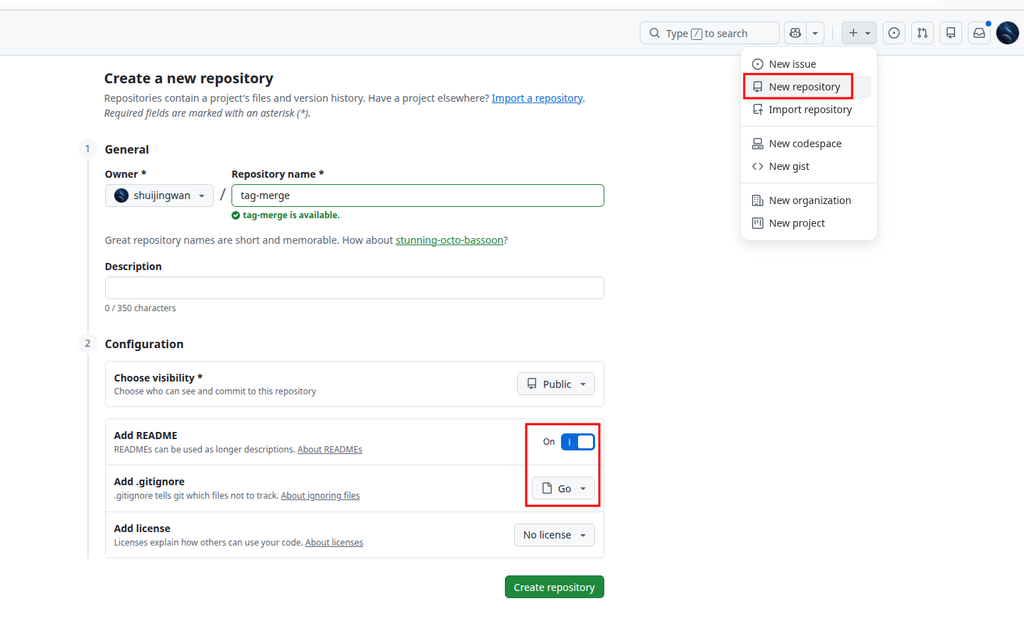
规范的工程从版本控制开始。在 GitHub 上新建一个仓库,命名为 tag-merge。为了简化初始化流程,勾选添加 README.md,并在 .gitignore 模板中选择 Go,这会自动帮我们忽略编译产生的二进制文件。
将仓库克隆到本地后,我们在终端进入项目目录,准备构建开发环境。
第三步:项目环境搭建与代码编写
为了保证环境的一致性且不污染宿主机,我们使用 Docker 进行容器化开发。项目的核心目录结构如下:
tag-merge/
├── .devcontainer/ # 容器开发环境配置(可选)
│ ├── devcontainer.json # 容器开发环境配置文件
├── data/ # 存放从数据库导出的原始 CSV 文件
│ ├── zh_tags.csv # 中文标签库
│ └── en_tags.csv # 英文标签库
├── output/ # 存放程序运行后生成的结果文件
│ └── tag_mapping_result.csv
├── .env.example # 环境变量示例文件
├── .env # 环境变量真实文件(已被 .gitignore 忽略)
├── .gitignore
├── docker-compose.yml
├── Dockerfile
├── go.mod
├── main.go # 核心业务逻辑
└── README.md
1. 配置环境变量
在项目根目录创建 .env 文件,填入刚才获取的百度 API 凭证:
BAIDU_APP_ID=你的APPID
BAIDU_SECRET_KEY=你的密钥
2. 编排 Docker 容器
编写 docker-compose.yml,将 .env 中的变量注入容器环境,同时挂载 data 和 output 目录以实现文件互通。
3. 编写核心 Go 逻辑
main.go 的核心处理流程如下:
- 读取并解析
en_tags.csv,以标签的 Name 和 Slug 为 Key,构建哈希索引。 - 读取并遍历
zh_tags.csv中的每一行中文标签。 - 调用百度翻译 API,将中文标签名翻译为英文。
- 将翻译结果在英文标签索引中进行碰撞查找。
- 若命中,记录为“API匹配成功”;若未命中,保留翻译结果并记录为“API未匹配(建议Slug)”。
- 将全量结果写入
output/tag_mapping_result.csv,为防止 Excel 乱码,写入前先输出 UTF-8 BOM 头。
同时,考虑到百度翻译标准版的 QPS 限制(1秒1次),在代码的循环中加入了 1.1秒 的休眠间隔。
第四步:运行脚本与数据处理
在终端中依次执行以下命令,启动容器并运行脚本:
# 构建并后台启动容器
docker compose up -d --build
# 进入容器终端
docker exec -it tag-merge sh
# 在容器内初始化依赖
go mod tidy
# 执行处理脚本
go run main.go
脚本运行后,由于有 1.1 秒的限频休眠,处理 3592 条数据需要约 65 分钟。从终端日志可以清晰地看到进度推进与匹配情况。
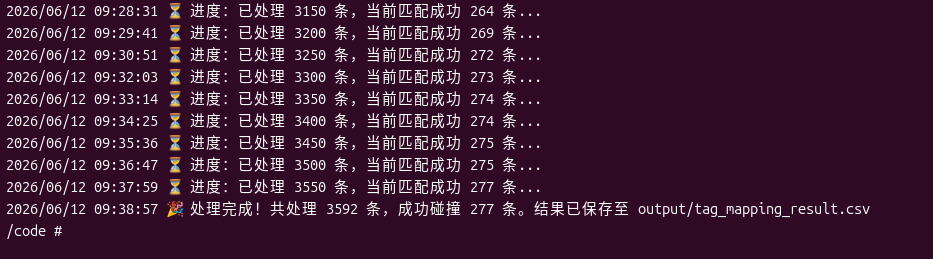
经过耐心等待,脚本最终输出完成提示:共处理 3592 条,成功碰撞 277 条。这意味着有 277 个中文标签在英文库中找到了精确对应,可以直接进行合并操作。
第五步:验证处理结果
退出容器,我们在宿主机的 output 目录下可以找到生成的 tag_mapping_result.csv。打开文件查看,结果格式规整,符合预期。
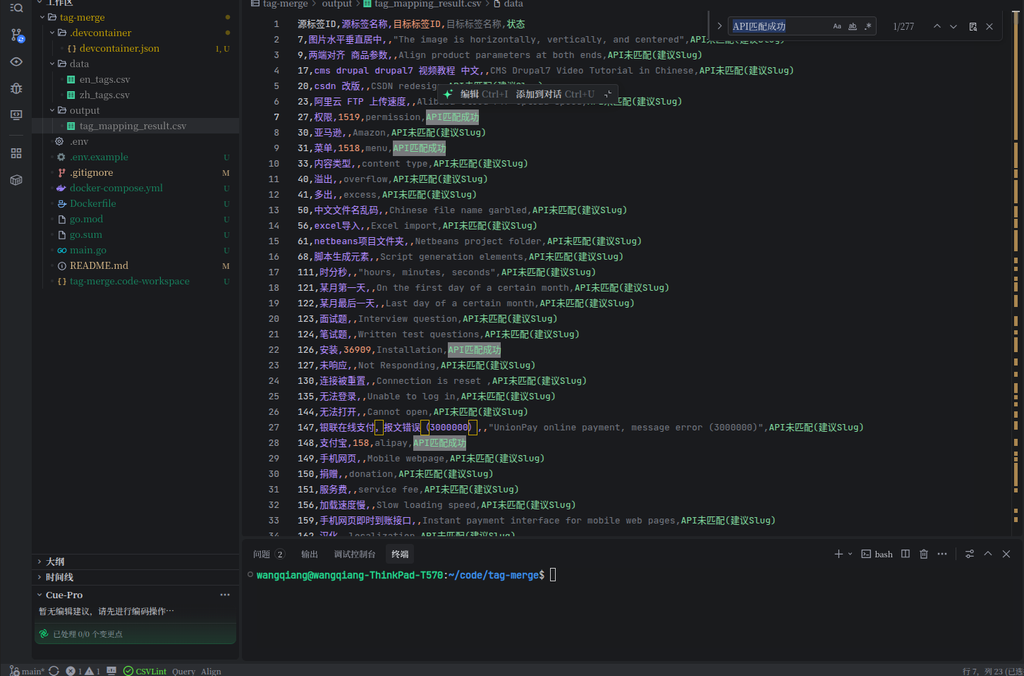
CSV 文件中包含了五个核心字段:
- 源标签ID / 源标签名称:原始的中文标签信息。
- 目标标签ID / 目标标签名称:匹配成功的英文标签信息。
- 状态:
API匹配成功:翻译后的英文在库中找到了已有标签(如:支付宝 -> alipay),这是最高优先级的处理项,可直接在 WordPress 中合并。API未匹配(建议Slug):英文库中无此标签,但提供了准确的英文翻译(如:加载速度慢 -> Slow Loading speed),可作为后续新增英文标签的 Slug 参考。
总结
通过 Go 脚本与百度翻译 API 的组合,我们以确定性的工程化方式,替代了不可控的大模型,成功完成了多语言标签的初步清洗。277 个精准匹配结果为后续的数据库操作提供了可靠的数据支撑。
不过,277 条仅占全量数据的 7.7%,仍有大量长尾标签需要进一步甄别与处理。在下一篇文章中,我将分享如何基于这份 CSV 结果,在 WordPress 中安全地执行标签合并与删除操作,彻底消灭 /en/tag/ 下的中文冗余网址。
WordPress 网站维护、性能优化与博客运营咨询
本站已持续运营超过 10 年,累计发布 1000+ 篇原创技术文章,长期实践 WordPress 网站建设、CDN / Cloudflare 配置、缓存优化、Google SEO、广告变现和多语言网站运营。
如果你的 WordPress 网站遇到访问慢、缓存异常、插件冲突、广告不显示、SEO 基础结构混乱、CDN 配置不确定等问题,可以联系我做一次远程技术排查。
适合以下用户:
✅ 个人博客站长
✅ WordPress 网站运营者
✅ 独立开发者与内容创作者
✅ SaaS 产品官网运营团队
✅ 希望优化网站速度与稳定性的站点
服务内容:
✅ WordPress 速度优化
✅ Cloudflare / CDN / 缓存配置排查
✅ 插件冲突与页面异常排查
✅ AdSense 广告显示问题排查
✅ SEO 基础结构检查
✅ 博客运营与商业化咨询
如需了解方案或交流相关问题,请直接联系我,并注明:WordPress 维护咨询。
联系方式:
Telegram:@shuijingwan
微信:13980074657
邮箱:shuijingwanwq@gmail.com
发表回复