
WP 博客多语言化实操





(5) 博客菜单翻译实操
















在维护 WordPress 多语言站点(尤其是使用 Polylang 插件)的过程中,标签泛滥是让无数站长头疼的问题。随着时间的推移,由于用户输入习惯不同或系统同步机制的局限,网站往往会积累大量同义词标签。
最典型的就是中英文混杂(如“支付宝”与“alipay”)以及微小差异(如“Redis缓存”与“Redis 缓存”,仅一个空格之差)。这些重复标签不仅让后台管理变得混乱,更会导致内容分散,严重稀释 SEO 权重。
最近,我彻底清理了网站的标签库,实现了 Polylang 环境下中英文标签的“原子级”安全合并。本文将分享这次实战的全过程。
一、 痛点:标签冗余与多语言陷阱
在未清理前,网站的标签生态面临着几个严峻的问题:
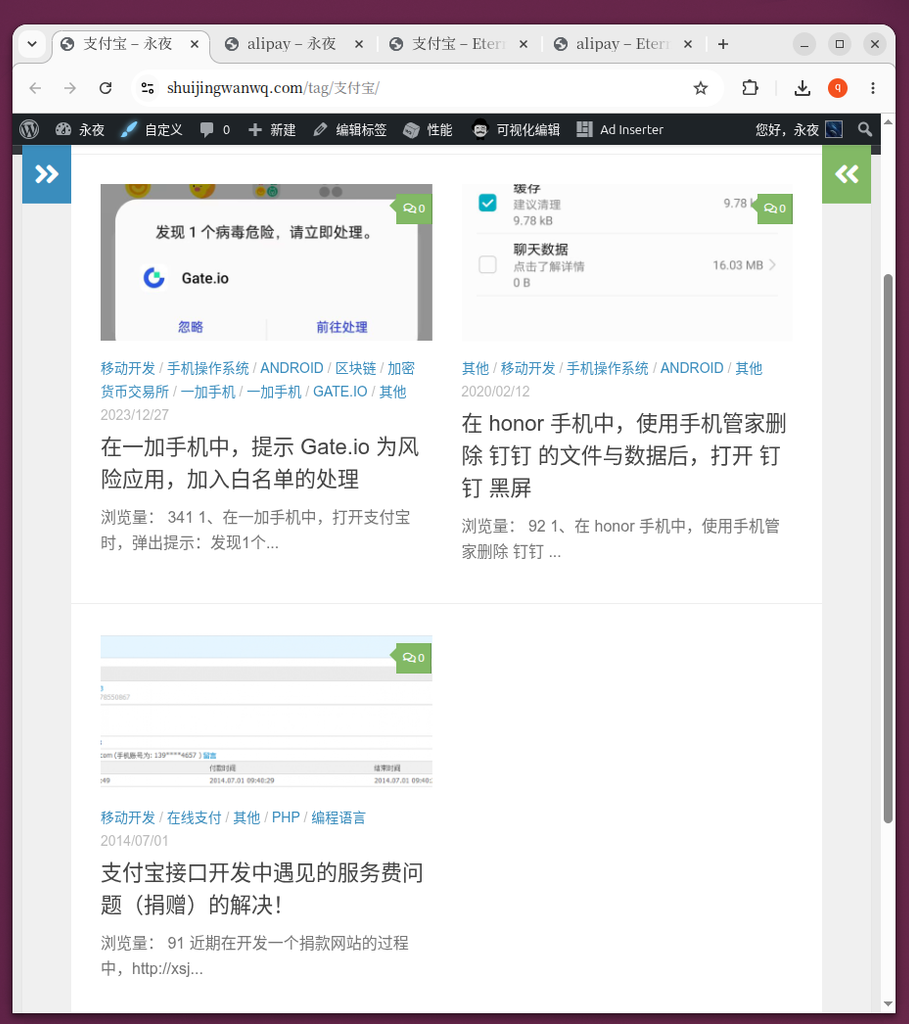
- 同义标签割裂内容:以支付相关文章为例,有些文章打了“支付宝”,有些打了“alipay”。读者点击标签时,只能看到部分文章,体验极差。
- 中英文映射断层:Polylang 虽然能关联中英文标签,但在实际运行中,由于缓存或同步脚本的瑕疵,很多中英文标签的翻译关系在底层是断开的,导致按官方函数根本查不到对应语言。
- 空格与大小写陷阱:“Redis缓存”与“Redis 缓存”,肉眼看似一样,但在数据库中是两个独立的 Term,直接合并极易漏掉。
二、 实战效果:从混乱到统一
为了彻底解决这一问题,我编写了一套具有“穿透式查找”和“原子性校验”的合并脚本。以下是清理前后的直观对比:
📸 清理前:四分五裂的标签页 (图 2, 3, 4, 5)
在脚本运行前,网站存在严重的同义标签分裂:
- 图 2 & 图 3:在中文环境下,访问
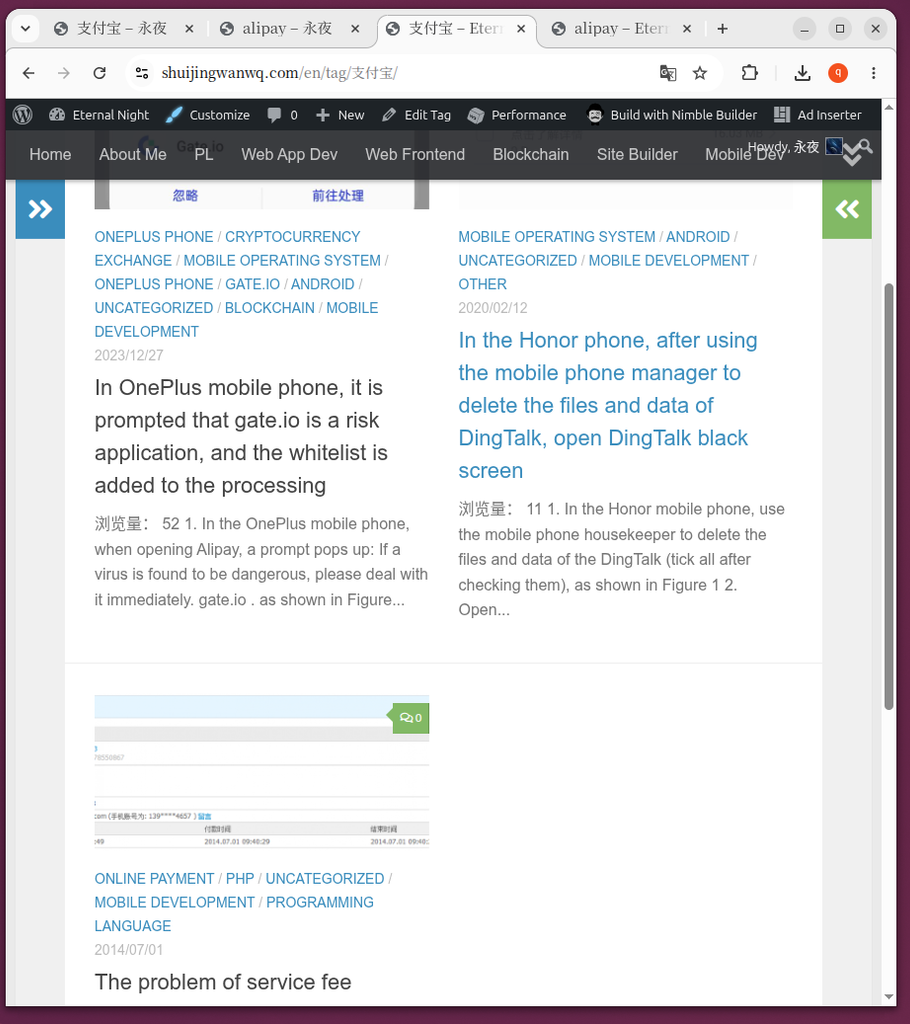
/tag/支付宝/和/tag/alipay/是两个独立的页面,文章被分散在两边。 - 图 4 & 图 5:在英文环境下,同样存在
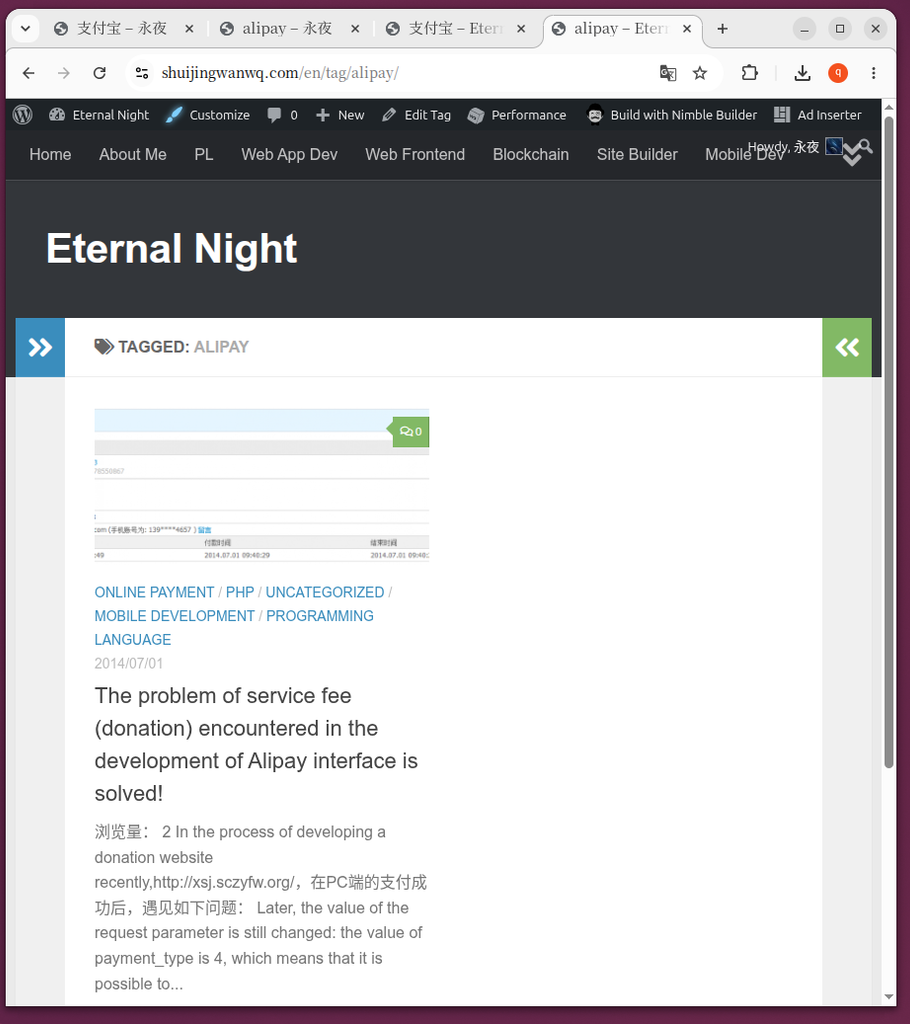
/en/tag/支付宝/和/en/tag/alipay/的割裂现象。
/tag/支付宝/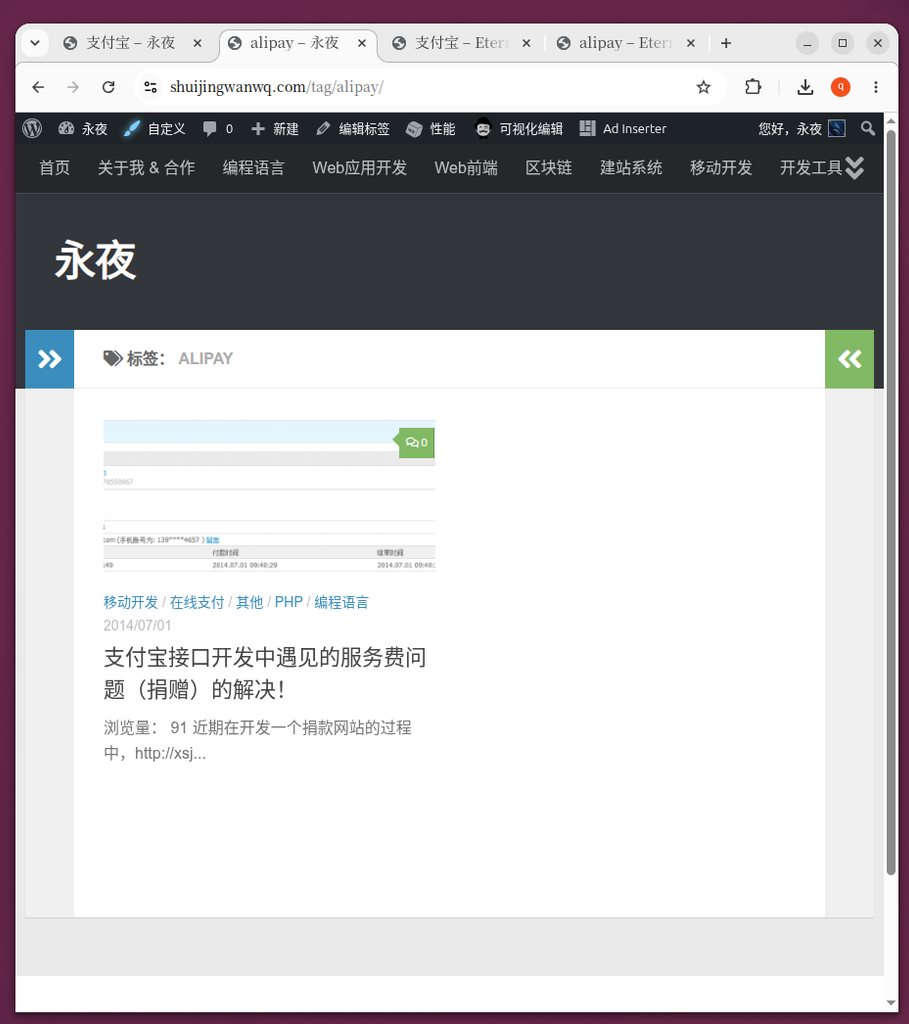
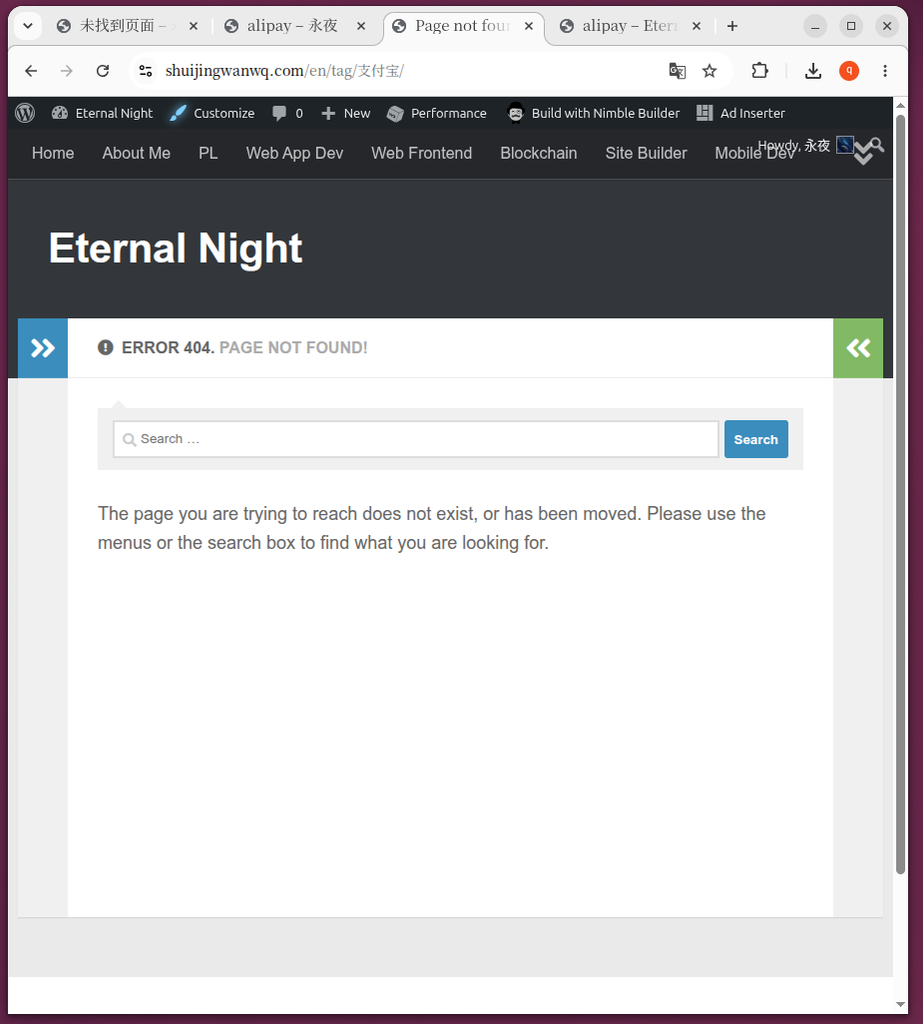
📸 清理后:归一与 404 的必然 (图 6, 7, 8, 9, 10)
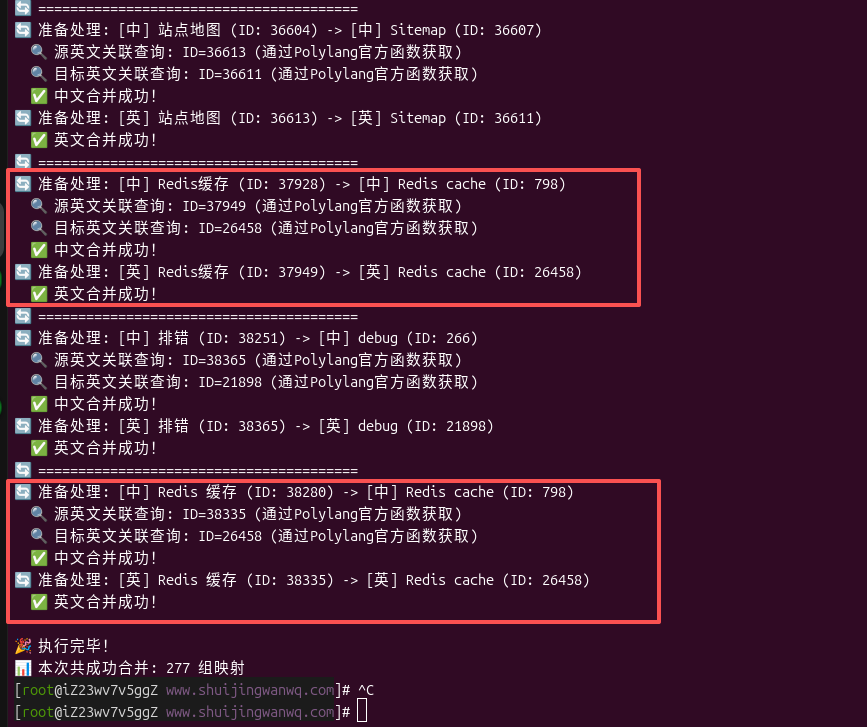
脚本执行后(如 图 6 终端日志所示),系统开始成对合并中英文标签。
合并成功的表现(图 8, 图 10):
- 图 8:访问
/tag/alipay/,原本属于“支付宝”标签的文章已经完美转移过来,合二为一。 - 图 10:英文版
/en/tag/alipay/同样聚拢了所有相关文章。
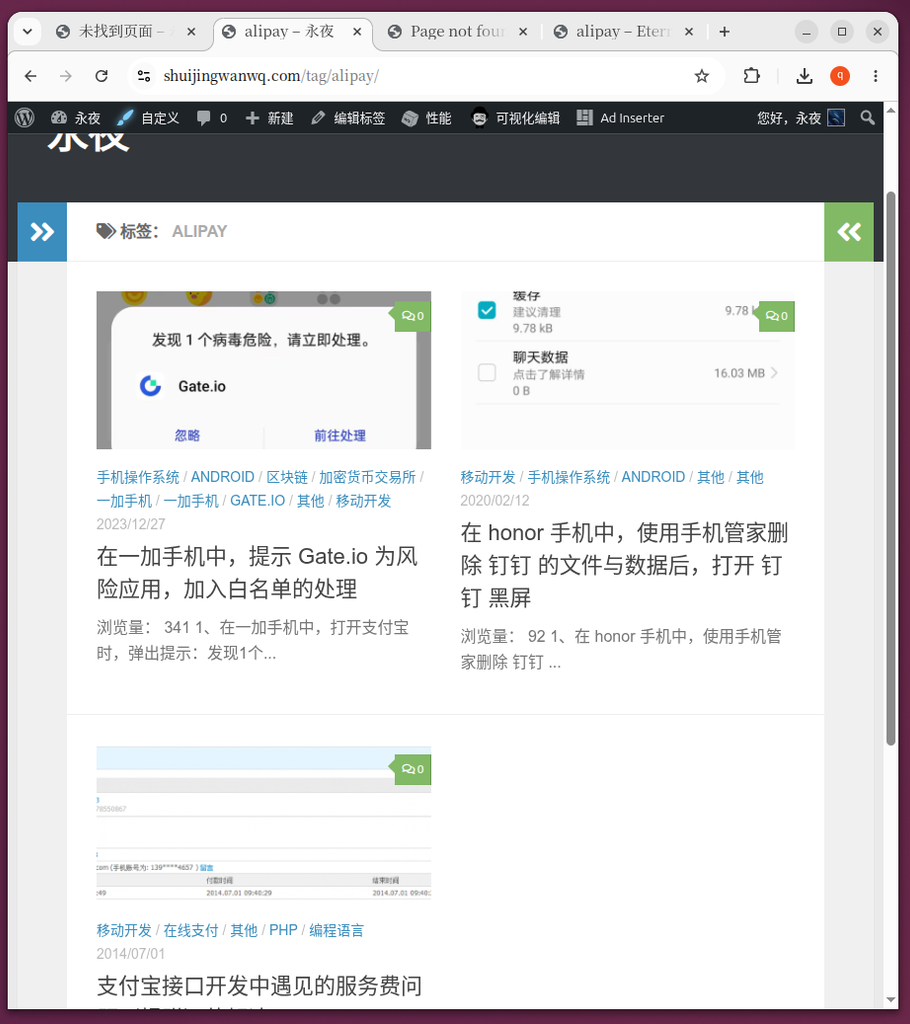
/tag/alipay/,原本属于“支付宝”标签的文章已经完美转移过来,合二为一。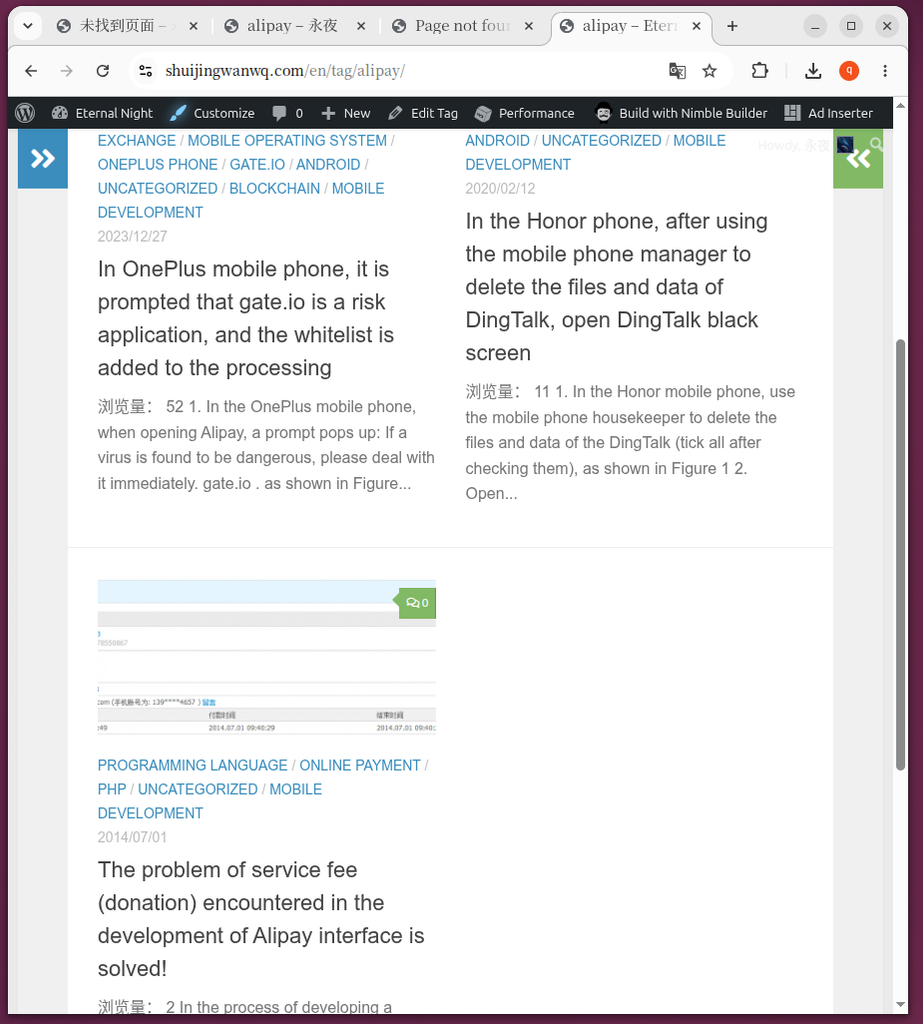
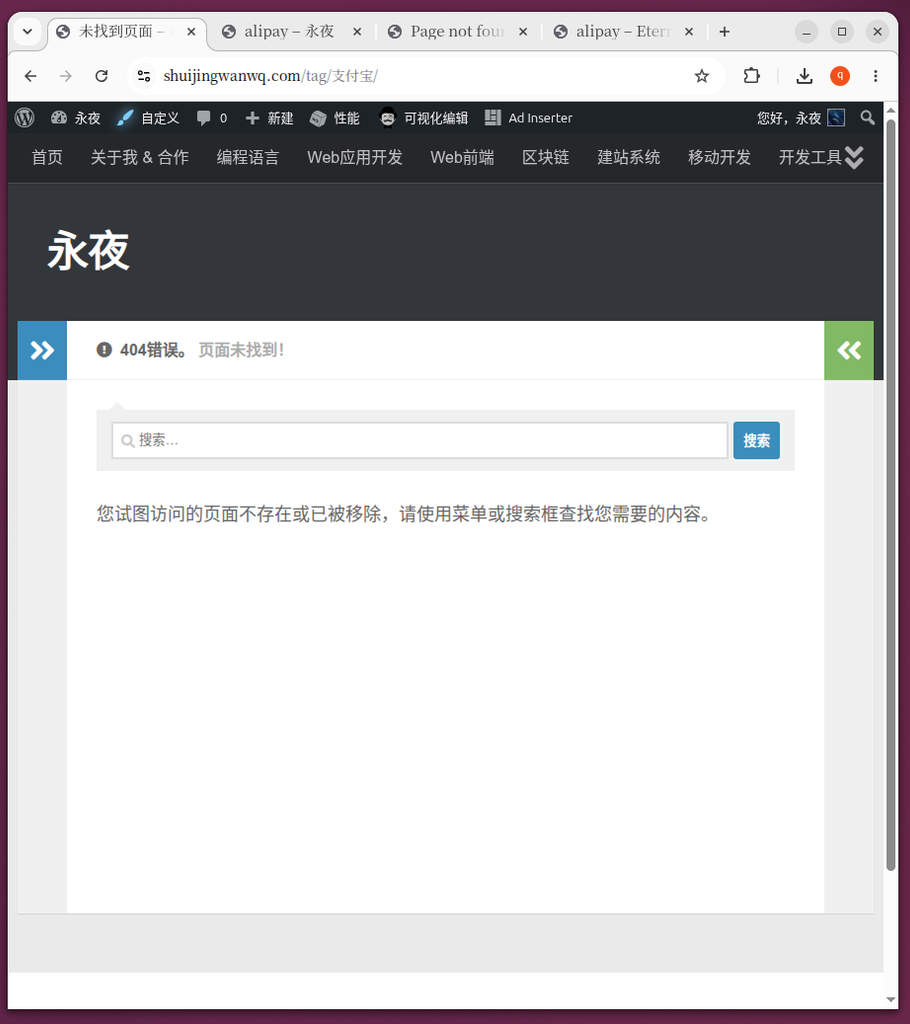
/en/tag/alipay/ 同样聚拢了所有相关文章。旧标签失效的表现(图 7, 图 9):
- 图 7 & 图 9:当你再访问旧的源标签 URL(如
/tag/支付宝/或/en/tag/支付宝/)时,出现了 404 错误。这是合并后的正常且预期的现象。因为 WordPress 的wp_delete_term函数在合并标签时,并不会自动为旧标签创建 301 重定向。旧标签作为实体已被删除,其 URL 自然失效。
三、 核心突破:解决“Redis缓存”与“Redis 缓存”的同义问题
正如终端日志(图 6)所展示的亮点:
准备处理: [中] Redis缓存 (ID: 37928) -> [中] Redis cache (ID: 798)
准备处理: [英] Redis缓存 (ID: 37949) -> [英] Redis cache (ID: 26458)
准备处理: [中] Redis 缓存 (ID: 38280) -> [中] Redis cache (ID: 798)
准备处理: [英] Redis 缓存 (ID: 38335) -> [英] Redis cache (ID: 26458)
“Redis缓存”(无空格)和“Redis 缓存”(有空格)这两个让人强迫症发作的标签,最终都被精准地合并到了统一的“Redis cache”下。
这得益于脚本在合并前,不依赖标签名称进行匹配,而是通过 CSV 映射表精准指定目标 ID。只要前期通过 API 或算法将它们识别为同义词并生成了映射表,无论名称差一个空格还是一个字母,都能一网打尽。
四、 技术揭秘:如何实现“零失误”的原子性合并?
在 CLI 环境下操作 Polylang 数据库犹如走钢丝,稍有不慎就会导致中英文不同步。这套脚本之所以能安全落地,核心在于以下三大机制:
- 穿透式英文标签查找:
在命令行下,Polylang 的缓存常常是缺失的,官方函数pll_get_term()经常返回空。脚本采用了四层防御查找:官方函数 -> Term Meta 直查 -> 逆向 Meta 搜索 -> 按别名+语言查库。正因为同步脚本会原样复制中文 Slug 到英文,最后这一层“按 Slug 查找”成为了最坚实的兜底,确保无论翻译关系怎么断,都能挖出真实的英文标签 ID。 - 绝对的“先查后删”原则:
脚本绝不会边删边查。如果在删除中文源标签后再去查它的 Slug 找英文,肯定查不到(因为 Slug 已随标签删除)。脚本会在执行任何删除操作前,把中英文的源 ID 和目标 ID 全部查询完毕并锁死在变量中。 - 严格的原子性校验(要么全做,要么全不做):
如果源标签有英文版,但目标标签的英文版缺失(且不自动创建以防数据污染),脚本会直接判定为异常,整行跳过,连中文也不合并。这避免了“中文合并了,英文没合并”的脏数据产生。
五、 附录:核心代码与数据格式
为了让遇到同样问题的朋友能够直接复用,以下是本次操作的数据格式规范和完整的 PHP 脚本代码。
1. CSV 映射表格式 (tag_mapping_result.csv)
脚本依赖一个预先准备好的 CSV 文件来决定合并策略。文件需放置在脚本同目录下的 output/ 文件夹中,格式如下:
源标签ID,源标签名称,目标标签ID,目标标签名称,状态
148,支付宝,158,alipay,API匹配成功
37928,Redis缓存,798,Redis cache,API匹配成功
38280,Redis 缓存,798,Redis cache,API匹配成功
- 前四列:明确指明源标签和目标标签的 ID 与名称(名称仅用于控制台日志展示,不参与逻辑匹配,完美解决空格等微小差异问题)。
- 第五列(状态):脚本只处理状态为
API匹配成功的行,其他状态的行会被安全忽略。
2. PHP 合并脚本 (merge-tags.php)
将以下代码保存为 merge-tags.php,放置在 WordPress 根目录下即可运行。
<?php
if (php_sapi_name() !== 'cli') {
die("❌ 请在命令行运行\n");
}
require __DIR__ . '/wp-config.php';
global $wpdb, $polylang;
$csv_file = __DIR__ . '/output/tag_mapping_result.csv';
if (!file_exists($csv_file)) {
die("❌ CSV文件不存在: {$csv_file}\n");
}
// 解析命令行参数
$test_ids = [];
$is_all = false;
$dry_run = in_array('--dry-run', $argv);
if ($dry_run) {
echo "🏃♂️ 【模拟执行模式】:仅输出将要执行的操作,不会修改数据库!\n\n";
}
$argv = array_diff($argv, ['--dry-run']);
if (isset($argv[1])) {
if ($argv[1] === '--all') {
$is_all = true;
echo "🚀 批量模式:处理 CSV 中所有 API匹配成功 的映射\n\n";
} else {
$test_ids = array_slice($argv, 1);
$test_ids = array_map('intval', $test_ids);
$test_ids = array_filter($test_ids);
if (empty($test_ids)) {
die("❌ 无效的ID参数。用法: php merge-tags.php 7 27 [--dry-run] 或 php merge-tags.php --all [--dry-run]\n");
}
echo "🧪 测试模式:仅处理源标签 ID 为 [" . implode(', ', $test_ids) . "] 的映射\n\n";
}
} else {
die("ℹ️ 请指定要测试的源标签ID,或使用 --all。\n用法: php merge-tags.php 7 27 [--dry-run]\n用法: php merge-tags.php --all [--dry-run]\n");
}
$target_lang = 'en';
$processed = 0;
/**
* 穿透式获取英文翻译ID函数
*/
function get_en_term_id_safe($zh_term_id, $target_lang) {
global $wpdb;
$en_id = pll_get_term($zh_term_id, $target_lang);
if ($en_id) return ['id' => $en_id, 'method' => 'Polylang官方函数'];
$translations = $wpdb->get_var($wpdb->prepare(
"SELECT meta_value FROM $wpdb->termmeta WHERE term_id = %d AND meta_key = '_pll_translations_post_tag'",
$zh_term_id
));
if ($translations) {
$trans = maybe_unserialize($translations);
if (!empty($trans[$target_lang])) return ['id' => $trans[$target_lang], 'method' => '当前Term的Meta直接提取'];
}
$search_string = sprintf('i:%d;', $zh_term_id);
$meta_values = $wpdb->get_col($wpdb->prepare(
"SELECT meta_value FROM $wpdb->termmeta WHERE meta_key = '_pll_translations_post_tag' AND meta_value LIKE %s",
'%' . $wpdb->esc_like($search_string) . '%'
));
if (!empty($meta_values)) {
foreach ($meta_values as $meta_value) {
$trans = maybe_unserialize($meta_value);
if (!empty($trans[$target_lang])) return ['id' => $trans[$target_lang], 'method' => '逆向Meta查找'];
}
}
$zh_term = get_term($zh_term_id, 'post_tag');
if ($zh_term && !is_wp_error($zh_term)) {
$en_terms = get_terms([
'taxonomy' => 'post_tag',
'slug' => $zh_term->slug,
'lang' => $target_lang,
'hide_empty' => false,
]);
if (!is_wp_error($en_terms) && !empty($en_terms)) return ['id' => $en_terms[0]->term_id, 'method' => '按别名+语言查找'];
}
return ['id' => 0, 'method' => '未找到'];
}
if (($handle = fopen($csv_file, 'r')) !== FALSE) {
fgetcsv($handle); // 跳过表头
while (($data = fgetcsv($handle)) !== FALSE) {
if (count($data) < 5) continue;
$source_zh_id = intval($data[0]);
$source_zh_name = trim($data[1]);
$target_zh_id = intval($data[2]);
$target_zh_name = trim($data[3]);
$status = trim($data[4]);
if ($status !== 'API匹配成功' || empty($target_zh_id)) continue;
if (!$is_all && !in_array($source_zh_id, $test_ids)) continue;
echo "🔄 ========================================\n";
echo "🔄 准备处理: [中] {$source_zh_name} (ID: {$source_zh_id}) -> [中] {$target_zh_name} (ID: {$target_zh_id})\n";
// ==============================================================================
// 核心逻辑:严格校验,绝不自动创建
// ==============================================================================
$source_en_info = get_en_term_id_safe($source_zh_id, $target_lang);
$target_en_info = get_en_term_id_safe($target_zh_id, $target_lang);
$source_en_id = $source_en_info['id'];
$target_en_id = $target_en_info['id'];
echo " 🔍 源英文关联查询: ID=" . ($source_en_id ?: '无') . " (通过" . $source_en_info['method'] . "获取)\n";
echo " 🔍 目标英文关联查询: ID=" . ($target_en_id ?: '无') . " (通过" . $target_en_info['method'] . "获取)\n";
$can_merge_en = false;
if ($source_en_id) {
// 源标签有英文版,目标英文也必须已存在
if ($target_en_id) {
$can_merge_en = true;
} else {
echo " ❌ 致命错误:源标签有英文(ID:{$source_en_id}),但目标标签无英文!为保证数据一致,跳过本次中英文合并!\n";
continue; // 直接中止整行操作,中文也不合并
}
} else {
echo " ℹ️ 源标签无英文翻译,仅合并中文即可\n";
}
// ==============================================================================
// 执行阶段:条件已全部满足,开始合并
// ==============================================================================
$zh_success = false;
// 1. 合并中文
if ($dry_run) {
echo " [模拟] 将删除中文源标签 {$source_zh_id},并将文章转移至 {$target_zh_id}\n";
$zh_success = true;
} else {
$result_zh = wp_delete_term($source_zh_id, 'post_tag', ['default' => $target_zh_id, 'force_default' => true]);
if (is_wp_error($result_zh)) {
echo " ❌ 中文合并失败: " . $result_zh->get_error_message() . " (英文也不再执行合并)\n";
continue;
}
echo " ✅ 中文合并成功!\n";
$zh_success = true;
}
// 2. 合并英文 (只有当中文成功,且校验允许合并英文时才执行)
if ($zh_success && $can_merge_en) {
echo "🔄 准备处理: [英] {$source_zh_name} (ID: {$source_en_id}) -> [英] {$target_zh_name} (ID: {$target_en_id})\n";
if ($dry_run) {
echo " [模拟] 将删除英文源标签 {$source_en_id},并将文章转移至 {$target_en_id}\n";
} else {
$result_en = wp_delete_term($source_en_id, 'post_tag', ['default' => $target_en_id, 'force_default' => true]);
if (is_wp_error($result_en)) {
echo " ❌ 英文合并失败: " . $result_en->get_error_message() . "\n";
} else {
echo " ✅ 英文合并成功!\n";
}
}
}
$processed++;
}
fclose($handle);
}
echo "\n🎉 执行完毕!\n";
echo "📊 本次共" . ($dry_run ? '模拟' : '') . "成功合并: {$processed} 组映射\n";
if ($dry_run) {
echo "💡 提示:去掉 --dry-run 参数后才会真正写入数据库。\n";
}
3. 运行方式
- 安全模拟(强烈建议首次运行):
php merge-tags.php 148 --dry-run - 单条实战:
php merge-tags.php 148 - 全量实战:
php merge-tags.php --all
六、 SEO 补救建议
如上文图 7 和图 9 所示,合并后旧标签 URL 会 404。如果你对 SEO 要求极高,建议在执行全量合并后,使用 Redirection 等插件,将高权重的旧标签 URL 批量 301 重定向到新的统一标签 URL 上,以将权重转移。
结语
通过这次彻底的清理,网站不仅告别了“Redis缓存”与“Redis 缓存”这类琐碎的同义标签,更解决了 Polylang 多语言关联不稳定的顽疾。代码的逻辑严谨性保障了数据的安全,让大数据量的标签清洗不再是噩梦。
WordPress 网站维护、性能优化与博客运营咨询
本站已持续运营超过 10 年,累计发布 1000+ 篇原创技术文章,长期实践 WordPress 网站建设、CDN / Cloudflare 配置、缓存优化、Google SEO、广告变现和多语言网站运营。
如果你的 WordPress 网站遇到访问慢、缓存异常、插件冲突、广告不显示、SEO 基础结构混乱、CDN 配置不确定等问题,可以联系我做一次远程技术排查。
适合以下用户:
✅ 个人博客站长
✅ WordPress 网站运营者
✅ 独立开发者与内容创作者
✅ SaaS 产品官网运营团队
✅ 希望优化网站速度与稳定性的站点
服务内容:
✅ WordPress 速度优化
✅ Cloudflare / CDN / 缓存配置排查
✅ 插件冲突与页面异常排查
✅ AdSense 广告显示问题排查
✅ SEO 基础结构检查
✅ 博客运营与商业化咨询
如需了解方案或交流相关问题,请直接联系我,并注明:WordPress 维护咨询。
联系方式:
Telegram:@shuijingwan
微信:13980074657
邮箱:shuijingwanwq@gmail.com
发表回复