WordPress Label Cleanup Practice (1): Failed attempts to match the big language model
In progressBlog Search Engine OptimizationDuring the process, I found a serious obstacle: due to the multilingual synchronization mechanism, a large number of redundant URLs such as /en/tag/ Chinese have been generated. This not only makes the tag library bloated, but also makes it difficult for search engines to correctly index English pages. In order to completely clear these URLs that are not good for SEO, I have to merge and clean the multilingual tags…
My WordPress site uses Polylang to implement bilingual in both Chinese and English. Since there is a synchronized PHP script, the Chinese label will be automatically copied to the English language every time a post is posted. Over time, data redundancy occurs: such as ‘Alipay’ and ‘alipay’, which exist at the same time in both Chinese and English languages.
This not only leads to the bloated tag library, but also produces /tag/Alipay And /en/tag/Alipay Such redundant URLs. My ultimate goal is very clear:clear up /en/tag/ The URL containing Chinese under the path. To this end, ‘Alipay’ must be merged into ‘alipay’ (or directly deleted) in Chinese language, and the same cleaning operation must be performed in English language.
At first, I thought that this kind of semantic matching task is very suitable for large language model processing, so I began to try to use the major models for data cleaning, but the end result forced me to turn the scheme to writing code.
Phase 1: Extraction and Integration of Raw Data
The premise of using a large model is to provide a complete dataset. The process of exporting full data in Alibaba Cloud DMS is quite cumbersome.
First of all, you need to query all the labels marked as Chinese by polylang and slug contains Chinese characters.
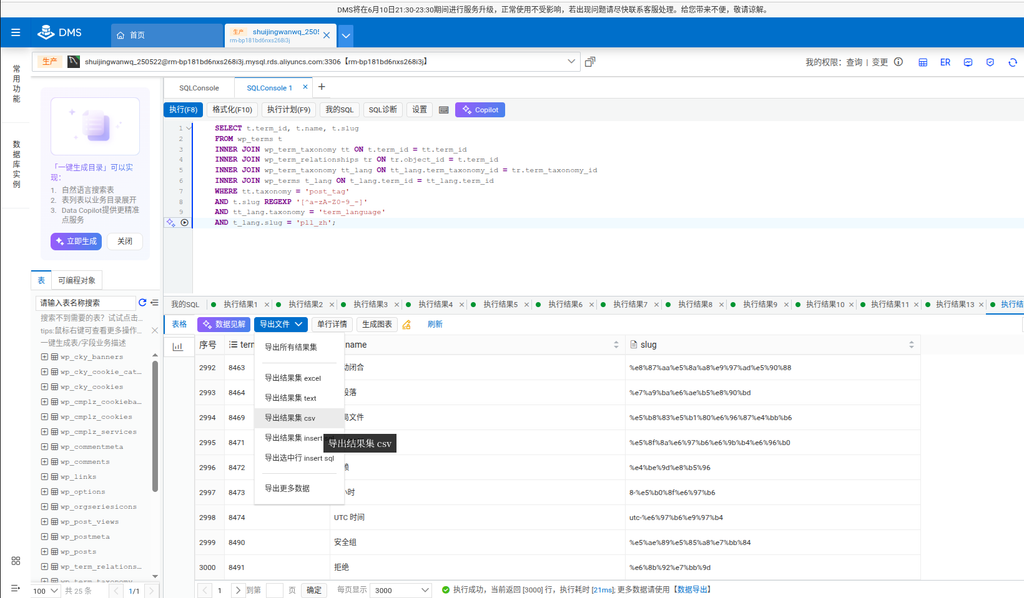
The query result of DMS only shows the first 3000 lines by default, and the number of my Chinese labels exceeds this limit. When trying to export in full, the system only provides Excel format and will still be divided into multiple files, which does not meet the subsequent processing requirements. Therefore, you can only perform the export operation of CSV format page by page, and finally manually integrate all the paging files into one complete data.
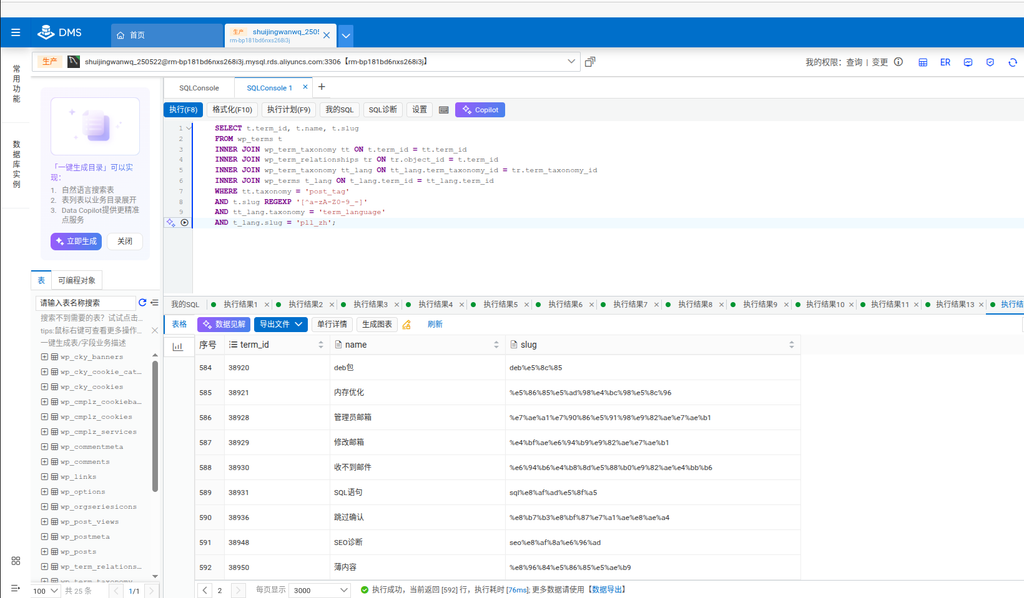
Secondly, you also need to export tags marked as Chinese, but slug does not contain Chinese characters. This part of the data is actually a pure English label under the Chinese language (for example, ‘aliPay’ is also present in the Chinese language). As for the Chinese-English mixed label, its slug must contain Chinese code, so it has been included in the previous batch of data. To export this part of the pure English tag data, you also need to go through the process of exporting and manual merge page pages.
After the above cumbersome data extraction and integration, the complete tag data set was finally obtained. I then took this data into the dialogs of the major language models for testing.
The second stage: the test performance of the big language model
The logic of the test is very clear: the model is required to compare the two labels list, map the same entries with the same semantics, and cluster the synonymous labels of pure Chinese at the same time. The file upload function is not used during the test, but the data text is pasted directly into the dialog box.
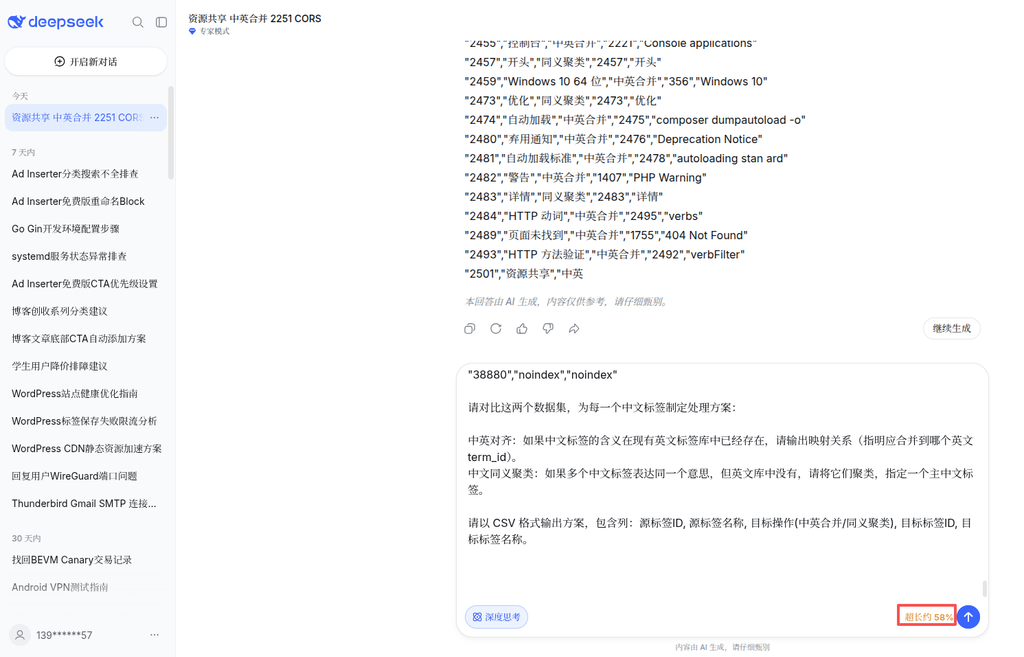
1. DeepSeek: Context overrun
First tested the DeepSeek model. After the data is pasted, the system prompts that the input length exceeds the limit of about 58%. The context window of a single conversation cannot hold data of this scale, and the task is terminated at the initial stage.
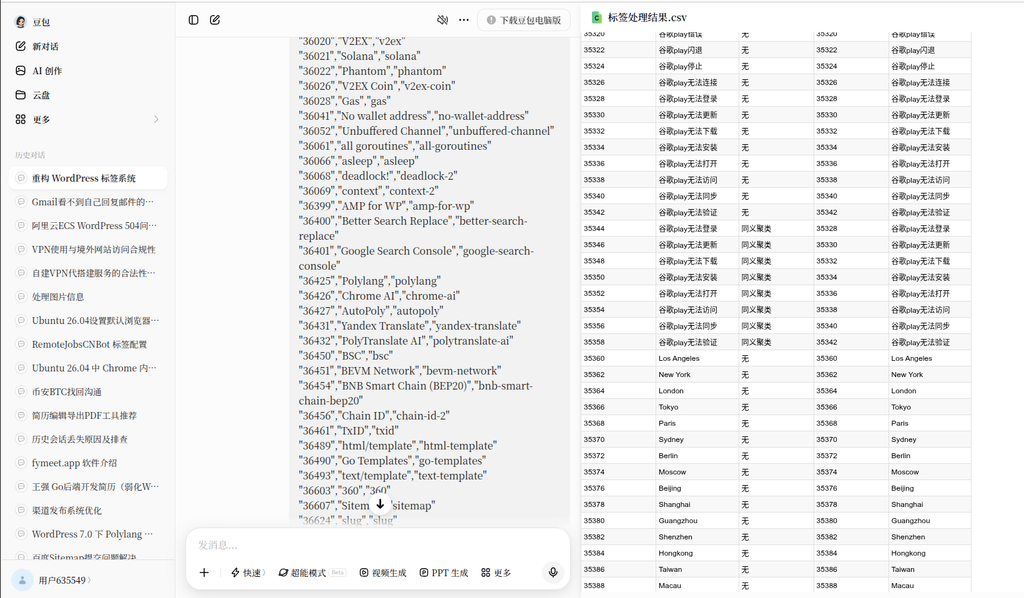
2. Bean bag: a serious hallucination problem
The bean packet model was then tested. The model received the complete data and outputs the results, but after sampling, it was found that there was a serious ‘illusion’ in its output. The model fails to perform accurate semantic matching, but instead fabricates many non-existent label aggregation relationships out of thin air. For example, it mistakenly clusters multiple Chinese tags under the ‘Google Play Can’t Open’ tab that doesn’t exist at all in a database. Such a result of the fact that the content of the format specification is actually wrong, if directly applied to the production library, will cause serious data pollution.
3. Tongyi Thousand Questions: Service Overload
In the case of poor performance of the aforementioned model, the test of Tongyi Thousand Questions is instead tested. However, due to the current number of visitors, the service is overloaded and cannot enter the actual test link.
4. ChatGPT: some are valid but cannot be fully processed
Finally tested ChatGPT (GPT-4O). Its performance is relatively good: when a large amount of data is pasted, the model automatically recognizes the data scale and converts it into a file upload mode. In addition, after the model analyzes the data structure, it actively recommends to split the mixed data into zh_tags.csv And en_tags.csv two separate files.
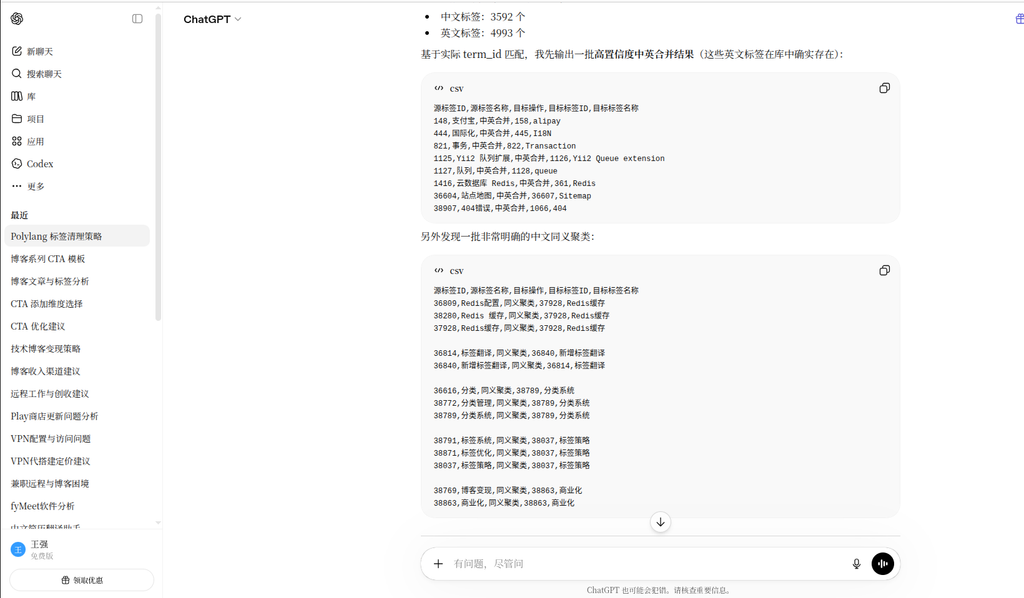
In the process of interaction, it does output a batch of high-confidence mapping results (such as ‘Alipay->alipay’, ‘queue->queue’). However, limited by the computing power overhead of context length and complex logic processing capabilities, the processing process stops after a very small part is completed, and the full throughput of more than 3,000 pieces of data cannot be completed.
Reflection and Scheme Reconstruction: Limitations of the Large Language Model
After the above test, it can be concluded that:For such tasks that require strict comparison of massive structured data and have zero tolerance rate, the probability generation mechanism of large language models has fundamental flaws. The illusion problems of context window limitations, easy interruption of the execution process, and inability to eradicate the illusion problems make them incompetent for such batch and high-precision data processing.
So I decided to give up the big-model-based semantic matching scheme and turn to deterministic engineering implementations:
- machine translation: Call Baidu General Translation API to stably convert Chinese labels to English.
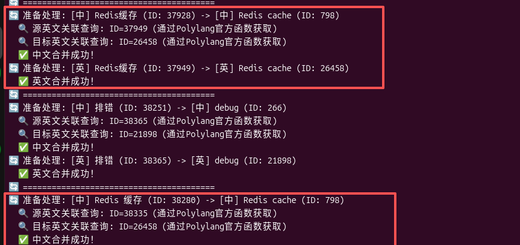
- Exact match: Use the Go script to perform a string-level precise collision of the translation result with the English tag library to generate a mapping relationship.
- automated execution: Relying on the script to complete the 3000+ API calls and data processing stably to prevent interrupts.
I can’t rely on a large model to do the cleaning of these thousands of multilingual tags, I can only regress the code. Only by accurately mapping and merging Chinese tags into English tags through the program can those redundant English Chinese websites be eliminated from the root, and complete this SEO in-depth cleanup. In the next article, I will record how to use the Go script to implement this multilingual data cleaning logic.