WordPress Label Cleanup Practice (3): Perfectly solve the problem of Polylang synonymous tag merger
In the process of maintaining a WordPress multilingual site (especially using the Polylang plugin), the flooding of tags is a headache for countless webmasters. Over time, websites tend to accumulate a large number of synonym labels due to the limitations of user input habits or system synchronization mechanisms.
The most typicalMixed Chinese and English(such as ‘Alipay’ and ‘alipay’) andminor difference(such as ‘redis cache’ and ‘redis cache’, there is only one space difference). These duplicate labels not only confusing background management, but also resulting in scattered content and severely diluted SEO weights.
Recently, I have thoroughly cleaned the label library of the website, and realized the ‘atomic-level’ safe merge of Chinese and English tags in the Polylang environment. This article will share the whole process of this actual combat.
1. Pain points: label redundancy and multilingual traps
Before cleaning, the label ecology of the website faces several serious problems:
- Synonymous label split content: Taking payment related articles as an example, some articles have typed ‘Alipay’, and some have been ‘alipay’. When readers click on the label, they can only see some articles, and the experience is extremely poor.
- Chinese and English mapping faults: Although polylang can be associated with Chinese and English tags, in actual operation, due to the flaws of cache or synchronization scripts, the translation relationship of many Chinese and English tags is disconnected at the bottom, so that the corresponding language cannot be found at all according to the official function.
- Spaces and Case Traps: ‘Redis cache’ and ‘Redis cache’, the naked eye may seem the same, but there are two independent terminals in the database, and it is easy to miss directly to merge directly.
2. Actual combat effect: from chaos to unity
In order to completely solve this problem, I have written a set of merge scripts with ‘penetrating lookup’ and ‘atomicity check’. Here is a visual comparison before and after cleaning:
📸 Before cleaning: the split tabs (Figure 2, 3, 4, 5)
Before the script runs, there is a serious synonymous split of the website:
- Figure 2 & Figure 3: In Chinese environment, visit
/tag/Alipay/And/tag/alipay/There are two separate pages, the article is scattered on both sides. - Figure 4 & Figure 5: In English, the same exists
/en/tag/Alipay/And/en/tag/alipay/splitting phenomenon.
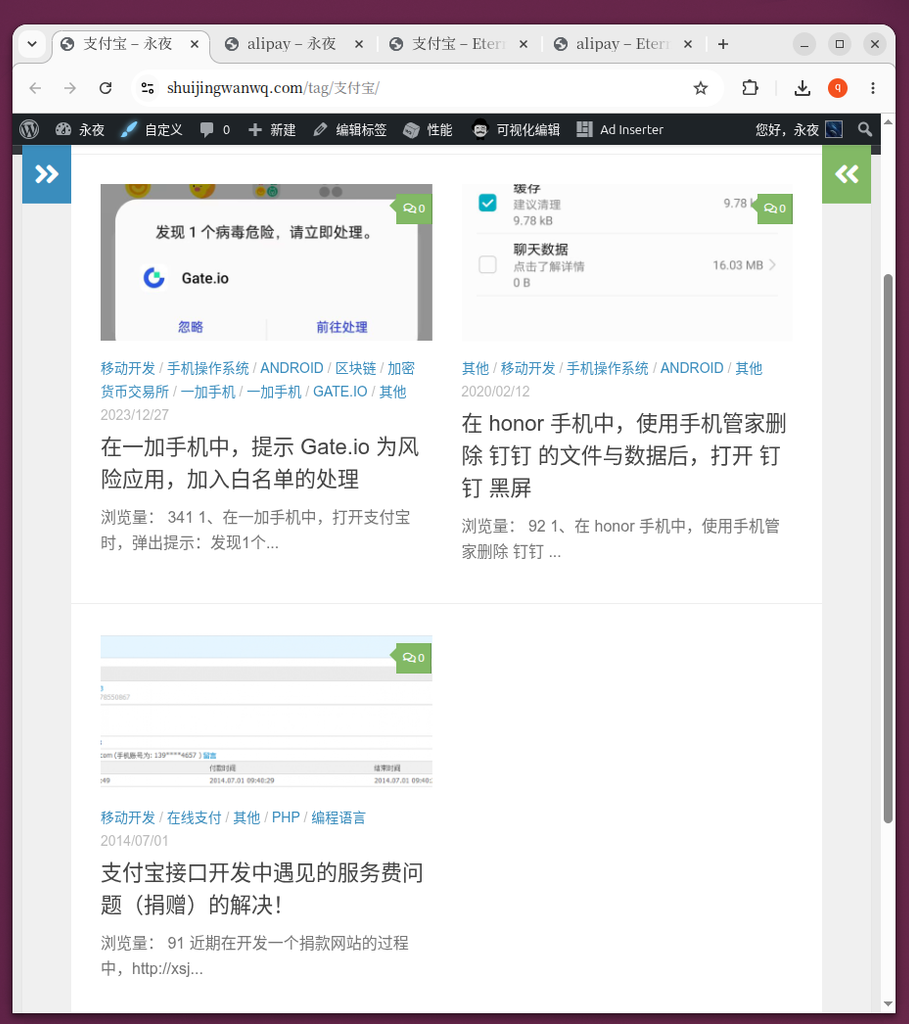
/tag/Alipay/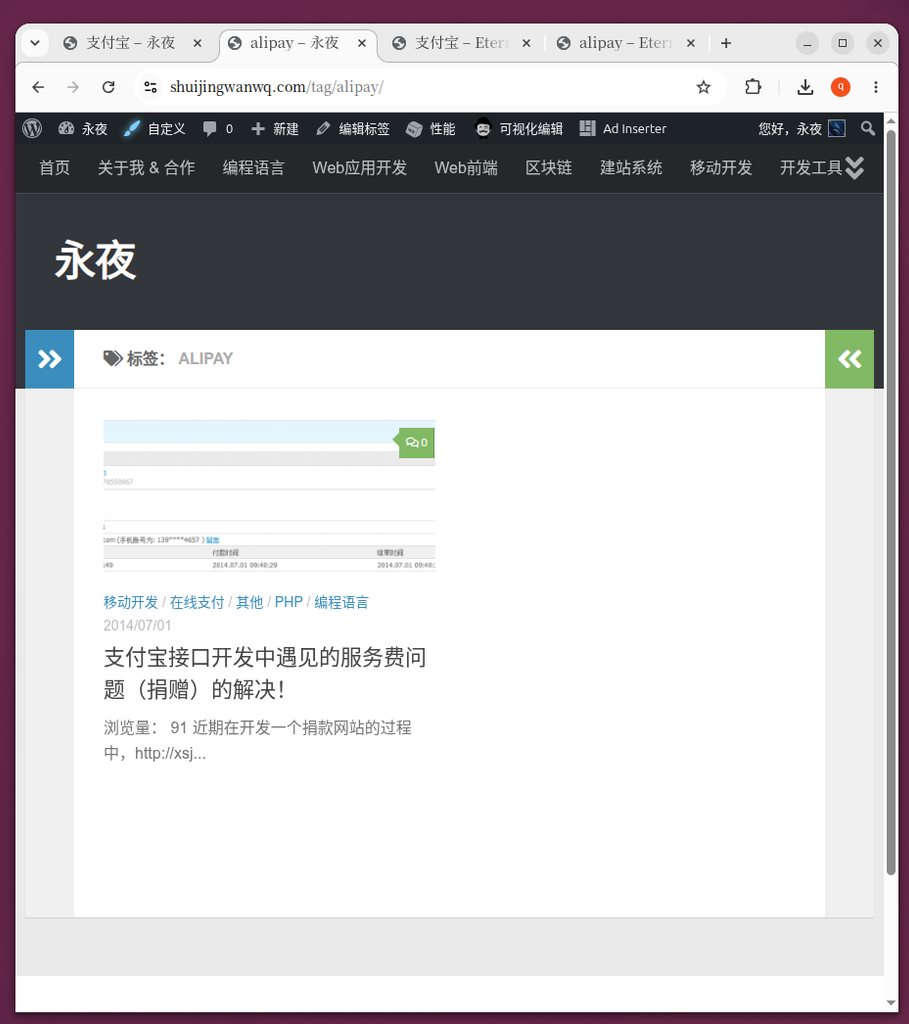
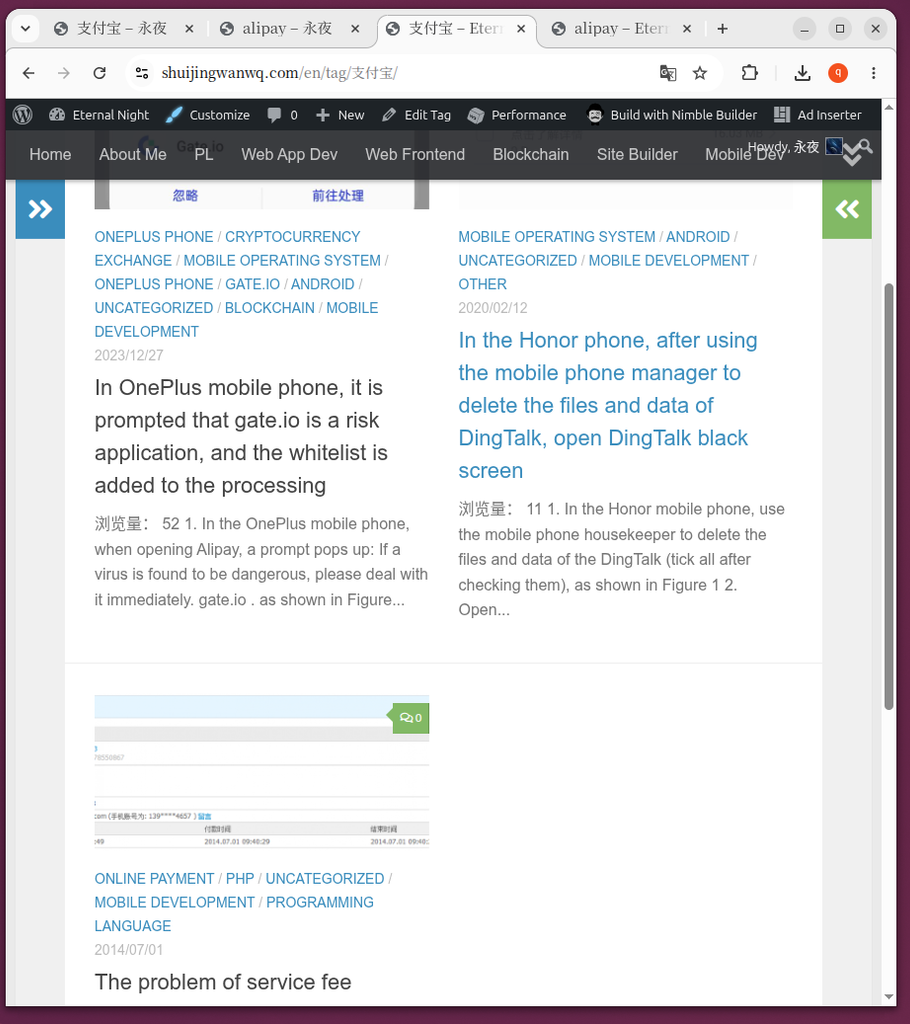
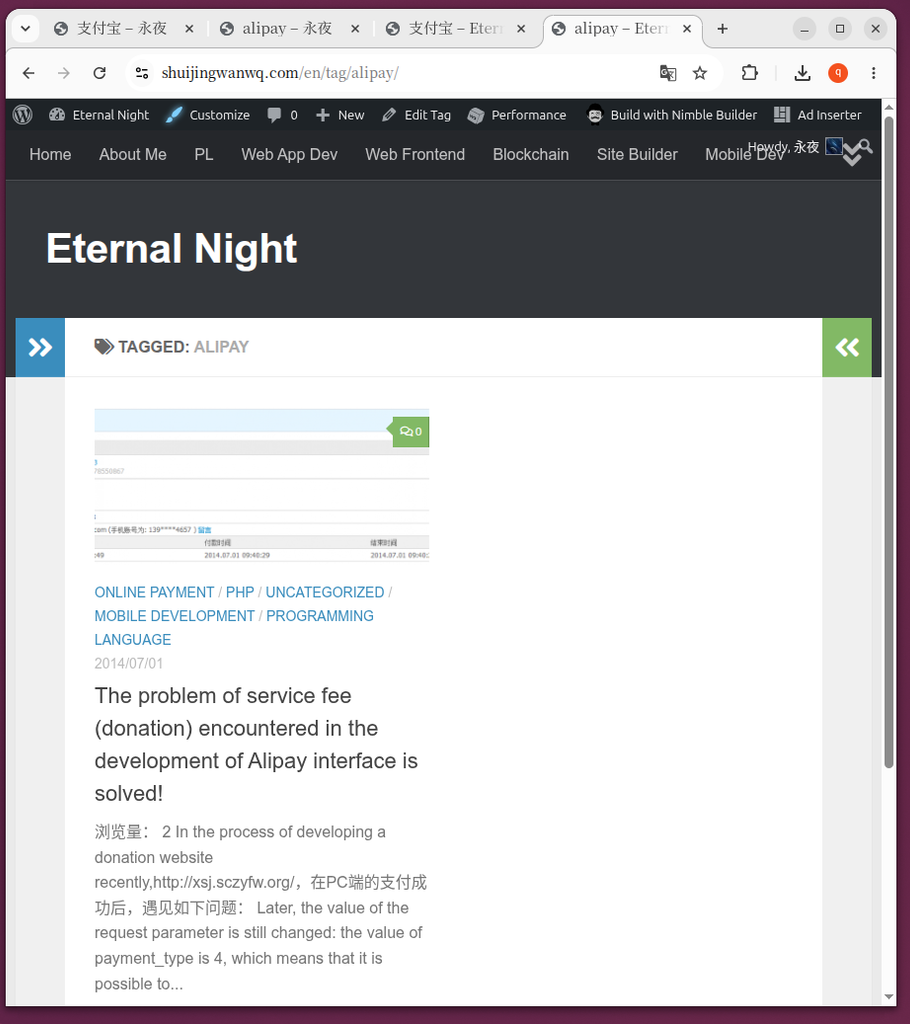
📸 After cleaning: the necessity of 404 (Figure 6, 7, 8, 9, 10)
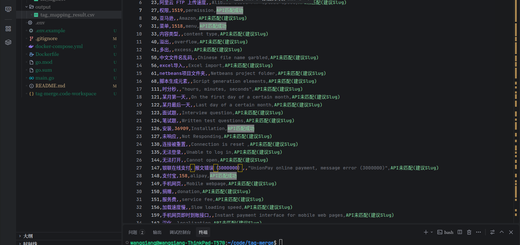
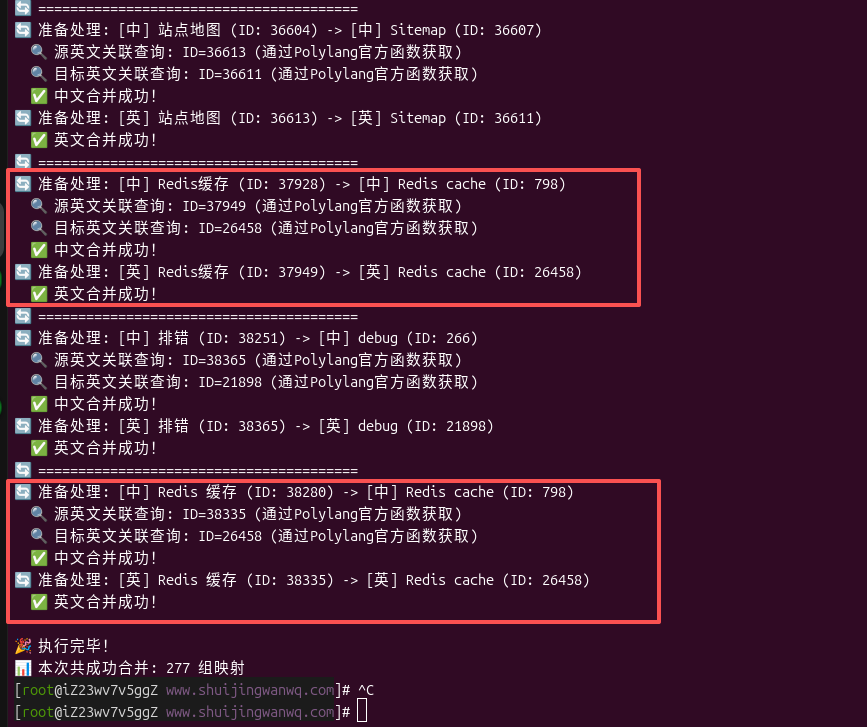
After the script is executed (such as Figure 6 As shown in the terminal log), the system starts to merge Chinese and English tags in pairs.
The performance of the merge is successful (Figure 8, Figure 10):
- Figure 8: visit
/tag/alipay/, the articles that originally belonged to the ‘Alipay’ label have been perfectly transferred and combined into one. - Figure 10: English version
/en/tag/alipay/All related articles were also gathered.
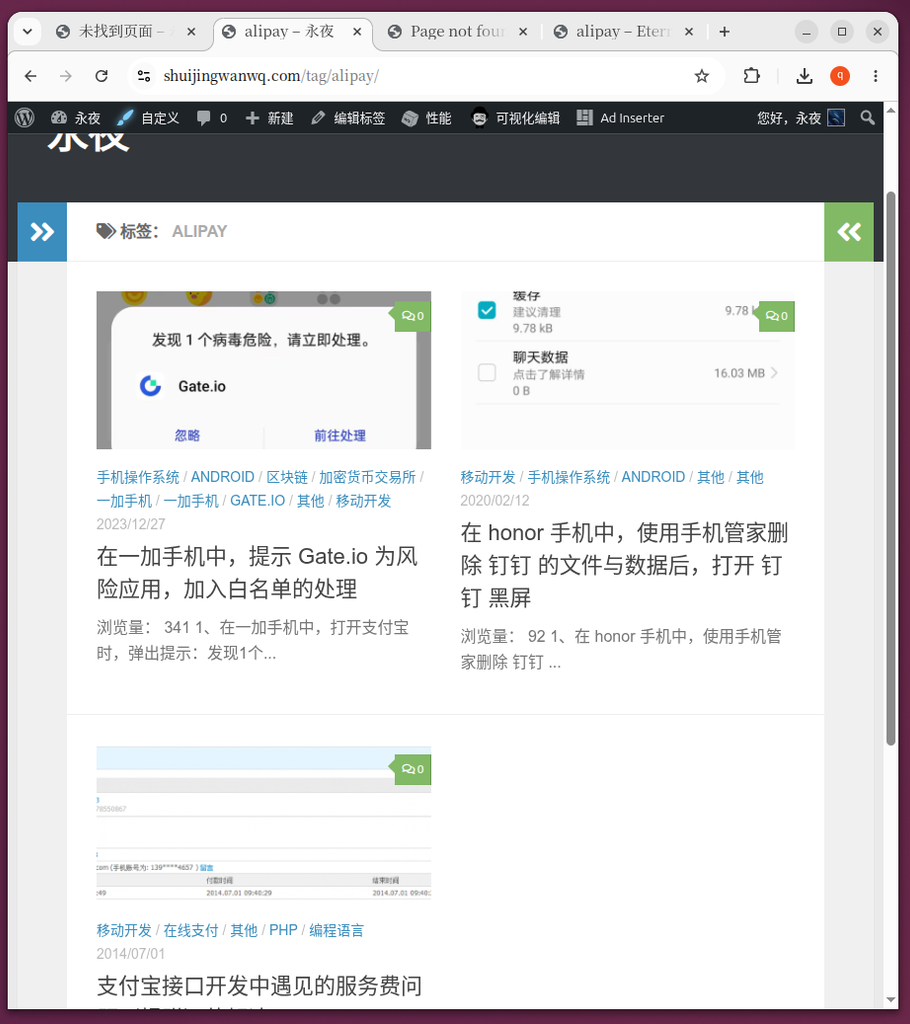
/tag/alipay/, the articles that originally belonged to the ‘Alipay’ label have been perfectly transferred and combined into one.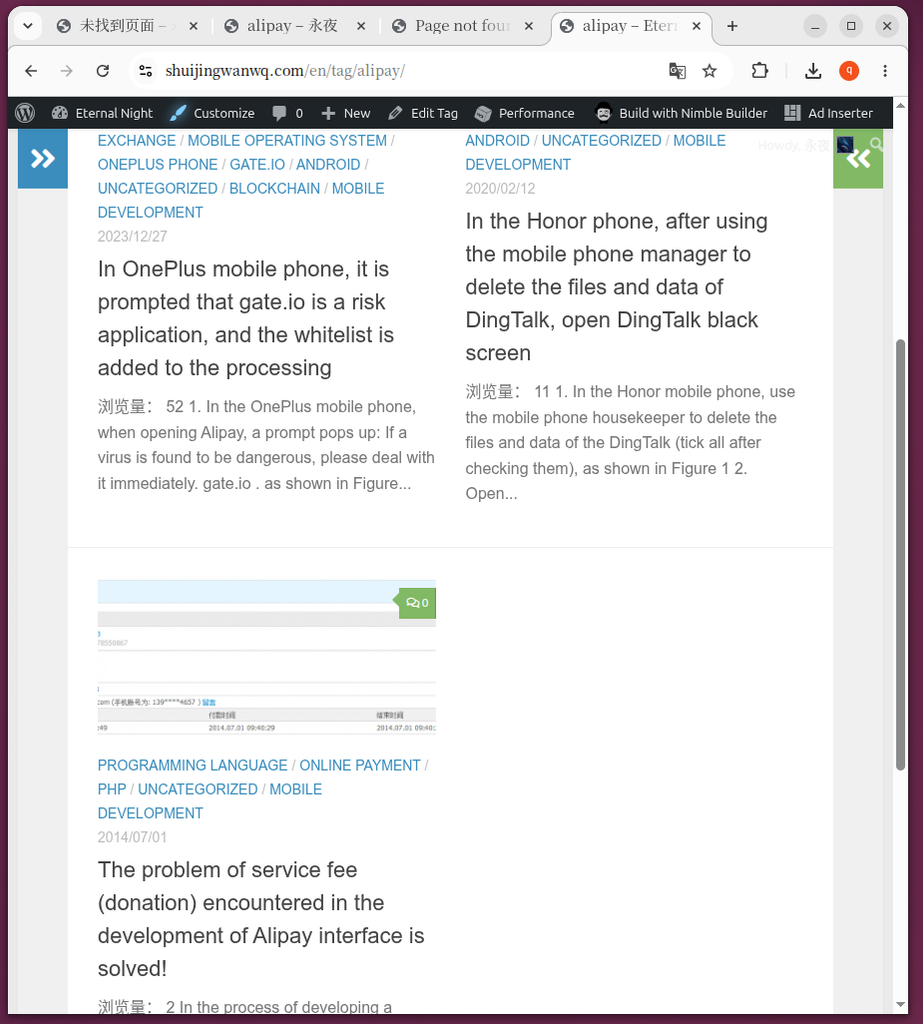
/en/tag/alipay/ All related articles were also gathered.The performance of the old label failure (Figure 7, Figure 9):
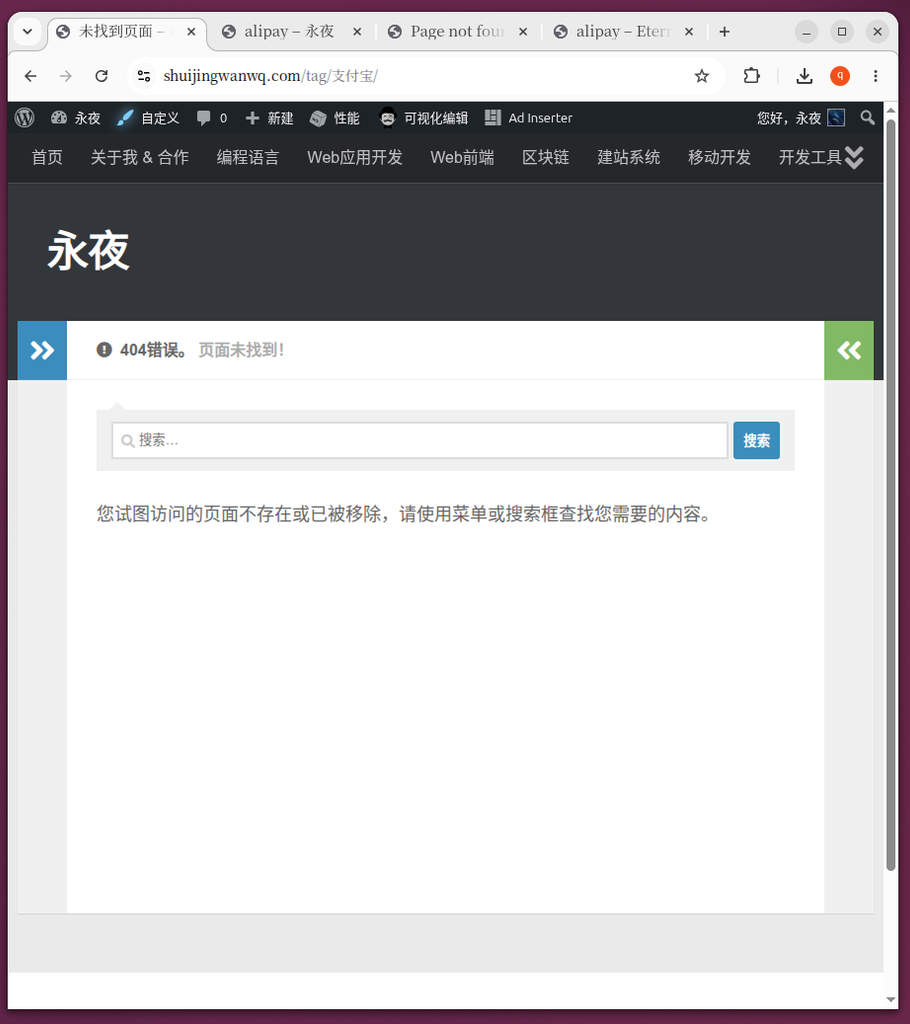
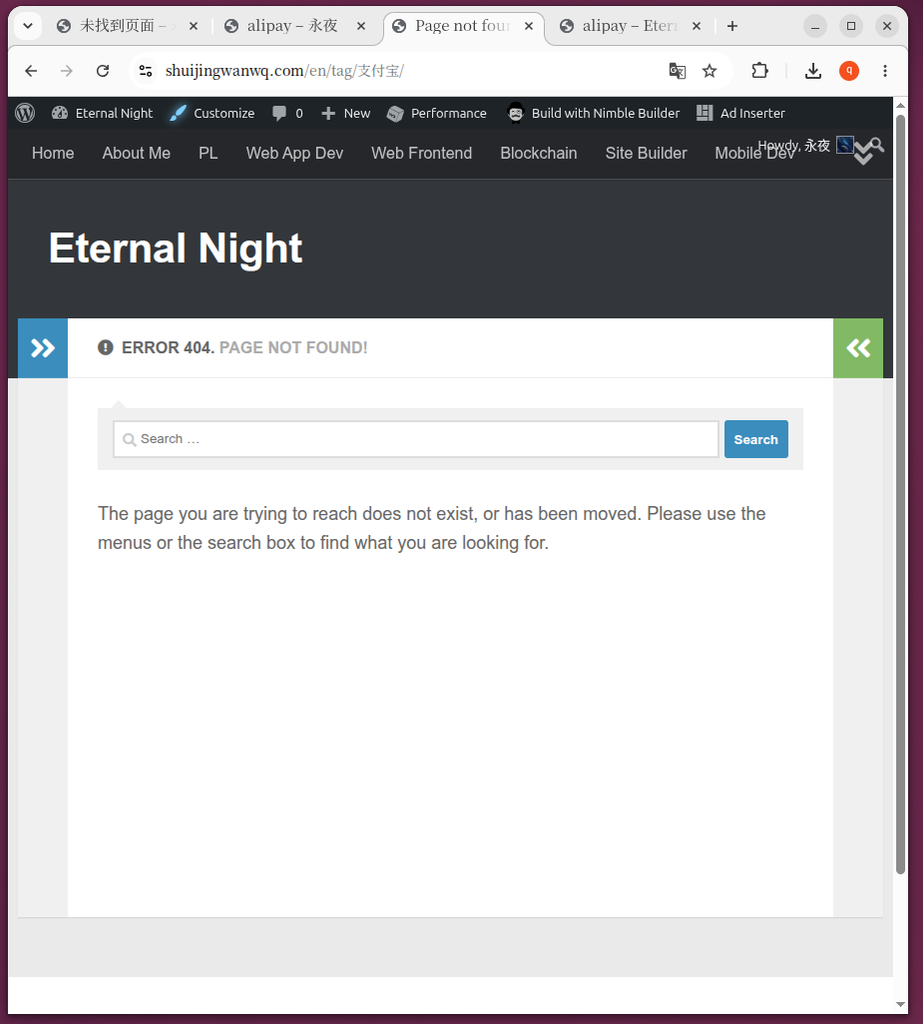
- Figure 7 & Figure 9: When you revisit the old source tag URL (such as
/tag/Alipay/Or/en/tag/Alipay/), there was a 404 error.This is a normal and expected phenomenon after the merger. because wordpressWP_DELETE_TERMFunctions do not automatically create 301 redirects for old tags when merging tags. The old tag has been deleted as an entity and its URL is naturally invalidated.
3. Core breakthrough: Solve the synonymous problem of ‘Redis cache’ and ‘Redis cache’
As shown in the Terminal Log (Figure 6):
准备处理: [中] Redis缓存 (ID: 37928) -> [中] Redis cache (ID: 798)
准备处理: [英] Redis缓存 (ID: 37949) -> [英] Redis cache (ID: 26458)
准备处理: [中] Redis 缓存 (ID: 38280) -> [中] Redis cache (ID: 798)
准备处理: [英] Redis 缓存 (ID: 38335) -> [英] Redis cache (ID: 26458)
The two ‘redis caches’ (no spaces) and ‘redis caches’ (with spaces) are the two tags that make the occurrence of obsessive-compulsive disorder, and they are finally precisely merged into the unified ‘redis cache’.
This is due to the script before the merge,Instead of relying on tag names to match, the target ID is specified with the CSV mapping table. As long as they are identified as synonymous through API or algorithm in the early stage and a mapping table is generated, no matter the name is a space or a letter, it can be wiped out in one go.
4. Technology Revealed: How to Realize the Atomic Merger of ‘Zero Mistakes’?
Operating the Polylang database in the CLI environment is like walking a steel wire, and a little carelessness will lead to the out of sync between Chinese and English. The reason why this script can be safely implemented is the following three mechanisms:
- Penetrating English Label Search:
Under the command line, the cache of polylang is often missing, the official functionpll_get_term()often return empty. The script uses four layers of defense search: official functions -> term meta direct search -> reverse meta search -> Search by alias + language. It is precisely because the synchronization script will copy Chinese slug to English as it is, and the last layer of ‘Find by slug’ has become the most solid foundation, ensuring that no matter how the translation relationship is broken, the real English tag ID can be dug up. - Absolute ‘check first and then delete’ principle:
Scripts will never be deleted while checking. If you delete the Chinese source tag and then check its slug to find English, you will definitely not be able to find it (because the slug has been deleted with the tag). The script will complete all the source ID and target ID in Chinese and English before performing any deletion operations and lock it in the variable. - Strict atomic check (either do it all, or do not do all):
If the source tag has an English version, but the English version of the target tag is missing (and it is not automatically created to prevent data pollution), the script will directly judge it as abnormal,Skip the whole line, not even Chinese is merged. This avoids the generation of dirty data that ‘Chinese is merged, English is not merged’.
5. Appendix: Core Code and Data Format
In order to allow friends who encounter the same problem to be reused directly, the following is the data format specification and complete PHP script code of this operation.
1. CSV mapping table format (tag_mapping_result.csv)
The script relies on a pre-prepared CSV file to decide the merge policy. The file should be placed in the same directory as the script output/ In the folder, the format is as follows:
源标签ID,源标签名称,目标标签ID,目标标签名称,状态
148,支付宝,158,alipay,API匹配成功
37928,Redis缓存,798,Redis cache,API匹配成功
38280,Redis 缓存,798,Redis cache,API匹配成功
- First four: Clearly specify the ID and name of the source and target tags (names are only used for console log display, do not participate in logical matching, and perfectly solve small differences such as spaces).
- Fifth column (status): The script only handles the status as
API matching successrows, other state lines are safely ignored.
2. PHP merge scripts (merge-tags.php)
save the following code as merge-tags.php, and put it in the WordPress root directory to run.
<?php
if (php_sapi_name() !== 'cli') {
die("❌ 请在命令行运行\n");
}
require __DIR__ . '/wp-config.php';
global $wpdb, $polylang;
$csv_file = __DIR__ . '/output/tag_mapping_result.csv';
if (!file_exists($csv_file)) {
die("❌ CSV文件不存在: {$csv_file}\n");
}
// 解析命令行参数
$test_ids = [];
$is_all = false;
$dry_run = in_array('--dry-run', $argv);
if ($dry_run) {
echo "🏃♂️ 【模拟执行模式】:仅输出将要执行的操作,不会修改数据库!\n\n";
}
$argv = array_diff($argv, ['--dry-run']);
if (isset($argv[1])) {
if ($argv[1] === '--all') {
$is_all = true;
echo "🚀 批量模式:处理 CSV 中所有 API匹配成功 的映射\n\n";
} else {
$test_ids = array_slice($argv, 1);
$test_ids = array_map('intval', $test_ids);
$test_ids = array_filter($test_ids);
if (empty($test_ids)) {
die("❌ 无效的ID参数。用法: php merge-tags.php 7 27 [--dry-run] 或 php merge-tags.php --all [--dry-run]\n");
}
echo "🧪 测试模式:仅处理源标签 ID 为 [" . implode(', ', $test_ids) . "] 的映射\n\n";
}
} else {
die("ℹ️ 请指定要测试的源标签ID,或使用 --all。\n用法: php merge-tags.php 7 27 [--dry-run]\n用法: php merge-tags.php --all [--dry-run]\n");
}
$target_lang = 'en';
$processed = 0;
/**
* 穿透式获取英文翻译ID函数
*/
function get_en_term_id_safe($zh_term_id, $target_lang) {
global $wpdb;
$en_id = pll_get_term($zh_term_id, $target_lang);
if ($en_id) return ['id' => $en_id, 'method' => 'Polylang官方函数'];
$translations = $wpdb->get_var($wpdb->prepare(
"SELECT meta_value FROM $wpdb->termmeta WHERE term_id = %d AND meta_key = '_pll_translations_post_tag'",
$zh_term_id
));
if ($translations) {
$trans = maybe_unserialize($translations);
if (!empty($trans[$target_lang])) return ['id' => $trans[$target_lang], 'method' => '当前Term的Meta直接提取'];
}
$search_string = sprintf('i:%d;', $zh_term_id);
$meta_values = $wpdb->get_col($wpdb->prepare(
"SELECT meta_value FROM $wpdb->termmeta WHERE meta_key = '_pll_translations_post_tag' AND meta_value LIKE %s",
'%' . $wpdb->esc_like($search_string) . '%'
));
if (!empty($meta_values)) {
foreach ($meta_values as $meta_value) {
$trans = maybe_unserialize($meta_value);
if (!empty($trans[$target_lang])) return ['id' => $trans[$target_lang], 'method' => '逆向Meta查找'];
}
}
$zh_term = get_term($zh_term_id, 'post_tag');
if ($zh_term && !is_wp_error($zh_term)) {
$en_terms = get_terms([
'taxonomy' => 'post_tag',
'slug' => $zh_term->slug,
'lang' => $target_lang,
'hide_empty' => false,
]);
if (!is_wp_error($en_terms) && !empty($en_terms)) return ['id' => $en_terms[0]->term_id, 'method' => '按别名+语言查找'];
}
return ['id' => 0, 'method' => '未找到'];
}
if (($handle = fopen($csv_file, 'r')) !== FALSE) {
fgetcsv($handle); // 跳过表头
while (($data = fgetcsv($handle)) !== FALSE) {
if (count($data) < 5) continue;
$source_zh_id = intval($data[0]);
$source_zh_name = trim($data[1]);
$target_zh_id = intval($data[2]);
$target_zh_name = trim($data[3]);
$status = trim($data[4]);
if ($status !== 'API匹配成功' || empty($target_zh_id)) continue;
if (!$is_all && !in_array($source_zh_id, $test_ids)) continue;
echo "🔄 ========================================\n";
echo "🔄 准备处理: [中] {$source_zh_name} (ID: {$source_zh_id}) -> [中] {$target_zh_name} (ID: {$target_zh_id})\n";
// ==============================================================================
// 核心逻辑:严格校验,绝不自动创建
// ==============================================================================
$source_en_info = get_en_term_id_safe($source_zh_id, $target_lang);
$target_en_info = get_en_term_id_safe($target_zh_id, $target_lang);
$source_en_id = $source_en_info['id'];
$target_en_id = $target_en_info['id'];
echo " 🔍 源英文关联查询: ID=" . ($source_en_id ?: '无') . " (通过" . $source_en_info['method'] . "获取)\n";
echo " 🔍 目标英文关联查询: ID=" . ($target_en_id ?: '无') . " (通过" . $target_en_info['method'] . "获取)\n";
$can_merge_en = false;
if ($source_en_id) {
// 源标签有英文版,目标英文也必须已存在
if ($target_en_id) {
$can_merge_en = true;
} else {
echo " ❌ 致命错误:源标签有英文(ID:{$source_en_id}),但目标标签无英文!为保证数据一致,跳过本次中英文合并!\n";
continue; // 直接中止整行操作,中文也不合并
}
} else {
echo " ℹ️ 源标签无英文翻译,仅合并中文即可\n";
}
// ==============================================================================
// 执行阶段:条件已全部满足,开始合并
// ==============================================================================
$zh_success = false;
// 1. 合并中文
if ($dry_run) {
echo " [模拟] 将删除中文源标签 {$source_zh_id},并将文章转移至 {$target_zh_id}\n";
$zh_success = true;
} else {
$result_zh = wp_delete_term($source_zh_id, 'post_tag', ['default' => $target_zh_id, 'force_default' => true]);
if (is_wp_error($result_zh)) {
echo " ❌ 中文合并失败: " . $result_zh->get_error_message() . " (英文也不再执行合并)\n";
continue;
}
echo " ✅ 中文合并成功!\n";
$zh_success = true;
}
// 2. 合并英文 (只有当中文成功,且校验允许合并英文时才执行)
if ($zh_success && $can_merge_en) {
echo "🔄 准备处理: [英] {$source_zh_name} (ID: {$source_en_id}) -> [英] {$target_zh_name} (ID: {$target_en_id})\n";
if ($dry_run) {
echo " [模拟] 将删除英文源标签 {$source_en_id},并将文章转移至 {$target_en_id}\n";
} else {
$result_en = wp_delete_term($source_en_id, 'post_tag', ['default' => $target_en_id, 'force_default' => true]);
if (is_wp_error($result_en)) {
echo " ❌ 英文合并失败: " . $result_en->get_error_message() . "\n";
} else {
echo " ✅ 英文合并成功!\n";
}
}
}
$processed++;
}
fclose($handle);
}
echo "\n🎉 执行完毕!\n";
echo "📊 本次共" . ($dry_run ? '模拟' : '') . "成功合并: {$processed} 组映射\n";
if ($dry_run) {
echo "💡 提示:去掉 --dry-run 参数后才会真正写入数据库。\n";
}
3. How to run
- Safe simulation(It is strongly recommended to run for the first time):
php merge-tags.php 148 --dry-run - single combat:
php merge-tags.php 148 - Full combat:
php merge-tags.php --all
6. SEO remediation suggestions
As shown in Figure 7 and Figure 9 above, the old tag URL will be 404 after the merge. If you have extremely high requirements for SEO, it is recommended to use plugins such as Redirection after performing a full merge, and redirect the high-weighted old tag URL batch 301 to the new unified tag URL to transfer the weights.
Epilogue
Through this thorough cleaning, the website not only bid farewell to the trivial synonym of ‘Redis cache’ and ‘Redis cache’, but also solves the unstable disease of polylang’s multi-language association. The logical rigor of the code ensures the security of data, so that the label cleaning of large amounts of data is no longer a nightmare.